
我花了很长时间从执行走向思考,又花了更长时间明白,真正的思考应该从哪里开始。
我搭了一座随时会倒的房子
做这件事之前,我已经在 AI Agent 这条路上走了一段时间。
从最早用 ChatGPT 的对话框,到开始认真写 System Prompt,到用 Dify 和 n8n 搭工作流,到后来进入 AI IDE,开始真正意义上的 Vibe Coding。每一层都踩过坑,每一层都有感悟。每一层我都以为自己到了一个新的台阶。
有一段时间,我在 Trae IDE 里搭了一套我自认为相当完整的 Agent 系统。负责战略思考的角色,负责内容创作的角色,负责数据分析的角色,几十个 Skill 文档定义各种原子能力。从外面看,这套系统有架构,有分工,有规范,很像一家公司。
但当我真正想用它做一件具体的事时,系统崩了。
不是技术崩了。是逻辑崩了。
Agent 之间互相踢皮球,指令在传递中不断衰减,信息在每一次移交里都会丢失一部分。我 80% 的时间在调试系统,只有 20% 的时间在做实际的事。
伪系统: 我不是在构建系统,我是在玩模拟经营游戏。我用管理大公司的逻辑,在运营一个只有我一个人的工作室。

我以为加一层规则框架就够了
第一次反思之后,我做了一件看起来很正确的事:给系统加 Harness。
Harness 这个词是我借来的——在软件工程里指测试框架,在 Agent 开发中指代一套行为约束系统:明确定义概念边界,规定执行流程,告诉 AI 什么该做什么不该做。
我开始认真思考什么是 Skill,什么是 Agent,它们之间的关系是什么。我写了执行规程,写了数据信任层级,写了路由矩阵,写了完成标准。系统开始变得更有秩序,AI 的行为变得更可预期。
但我隐约感觉哪里不对。
规则越写越细,文档越来越多,规范越来越完整——但这种”完整”里有一种脆弱。
某一天我打开规则文件夹,看着里面那些条目,突然发现一个问题:
这些规则是怎么来的?
大多数是踩坑之后总结的。AI 某次做错了某件事,我写一条规则防止它再做。AI 某次在两个任务之间搞混了,我写一条规则帮它区分。
本质上,这是从实践中归纳的补丁集合,不是从原则中推导的规则体系。
区别在哪?补丁处理的是已知的错误。原则处理的是所有情况——包括还没见过的情况。
误区: 我用执行的方式,在解决一个思考层面的问题。
我开始反过来问:数学大厦是怎么建的
我是金融工程出身,对数学不陌生,但从来没想过用数学的建造逻辑来思考 Agent 系统。
直到我开始认真问自己一个问题:人类有没有建过一个内部完全自洽、每一个结论都能追溯到最底层、经得起两千年推敲的知识体系?
有。是数学。
数学大厦的建造逻辑和我搭 Agent 系统的直觉截然相反。我是先做,遇到问题,再加规则。数学是先定义最底层的东西,然后从底层向上,每一步都严格推导。
这个过程不是一帆风顺的。数学史上经历了多次危机,每次危机都把地基挖得更深:
 数学每一次进步,都从承认错误、重建地基开始
数学每一次进步,都从承认错误、重建地基开始
这背后有一个反直觉的结论:数学的每一次进步,都是从承认错误、重建地基开始的,不是从加更多规则开始的。
罗素发现悖论的那一天,他没有给弗雷格的系统打补丁。他说,地基错了,重建。
这不是失败,是诚实。
但还有一件事让我印象更深。在公理之前,数学还有一类更基础的东西:未定义原语(undefined primitives)。在 ZFC 集合论里,“集合”、“元素”、“属于”(∈)这三个词从来没有被定义过。
不是数学家忘了定义它们。是它们不能被定义——所有的定义都要用到它们,所以它们必须先于定义存在。
数学家的做法是:用公理来刻画它们的行为——告诉你 ∈ 应该满足什么性质,但不告诉你 ∈ 是什么。
定义和刻画,是两件不同的事。这个区分后来让我想清楚了一个困惑很久的问题——但那是另一篇文章的故事。
用三把刀切我的系统
我把数学标准拿来审视自己的系统,用三把刀:独立性、一致性、完备性。
独立性:公理之间不能互相推导
就像建筑的承重柱——如果一根柱子其实是搭在另一根柱子上的,那它不是独立的承重结构,拆掉它不会改变任何东西。
我扫了一眼自己的原则列表。“简洁性”这条原则——最小可工作方案优先,三行相似代码优于一个过早的抽象——可以直接从奥卡姆剃刀推导出来。
奥卡姆剃刀: 十四世纪一个叫奥卡姆的修士提出,当两种解释都能说明同一个现象时,选择更简单的那个。把这条原则应用到解决方案上,自然就得到”简洁性”。
所以”简洁性”不是独立公理,是推论。我把它从公理列表里降级了。
在我的系统里,奥卡姆剃刀的实际含义是:每次想新增一个规则、一个角色、一个文件,先问不加它,系统会缺失什么?
一致性:规则之间不能产生矛盾
我发现系统里存在一个三角冲突。想象这样一个场景:我让 AI 帮我做一件事,这件事需要执行一个不可逆的操作。
- 可逆性: 规则要求可撤销的行动优先,不能撤销就暂停确认
- 所有权: 规则要求接到任务就完成它,不要把复杂性推回给用户
- 奥卡姆: 规则要求最小化操作,包括最小化确认流程的开销
三条原则同时触发,指向三个不同方向。谁说了算?原来的文档没有答案。
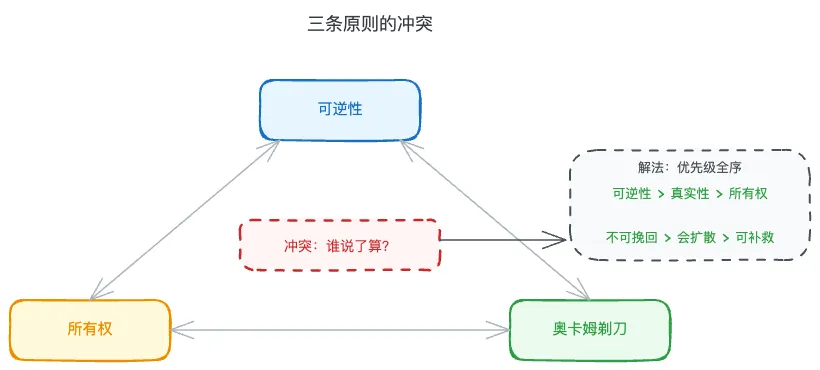 三条原则的冲突,与优先级全序的解法
三条原则的冲突,与优先级全序的解法
这意味着每次遇到这种情况,AI 只能凭自己的判断——而”凭判断”正是我建立规则体系想要避免的事。
解法是给公理加一个明确的优先级全序。可逆性失守,代价不可挽回;真实性失守,污染会扩散;所有权失守,效率损失可以补救。优先级从高到低,冲突时有了机械可执行的答案。
完备性:系统能处理它声称覆盖的所有情况
我的路由矩阵只写了”是什么”,没有写”为什么”。它是一张查找表,不是一套推导出来的决策逻辑。
更大的问题是,系统没有类型层。
想象一下语法。在写任何句子之前,语言需要先定义名词、动词、形容词是什么。没有这些基本定义,语法规则就没有操作对象。
在我的系统里,Skill、Agent、Task、Deliverable(可交付产出)这些核心对象从来没有被正式定义过。规则在操作一堆没有类型的概念,就像一门只有动词没有名词的语言。
在建立类型层的过程里,我遇到了一个微妙的问题:什么需要定义,什么不需要?
答案是只定义如果不给出定义,AI 会做错的事情。
“Skill 必须无状态”需要定义,因为没有这条约束,AI 可能写出持有对话历史的 Skill,在复用时产生不可预期的结果。“README 是什么”不需要定义,AI 从训练中已经知道,且理解和我们需要的一致。边界在于:是否存在需要我们施加的行为契约。
三把刀检查结果汇总
| 测试 | 发现的问题 | 修复方式 |
|---|---|---|
| 独立性 | ”简洁性”可从奥卡姆剃刀直接推导,不是独立公理 | 降级为推论 |
| 一致性 | 可逆性 / 所有权 / 奥卡姆三角冲突,无裁判规则 | 加入优先级全序 |
| 完备性 | 路由只有”是什么”,核心对象无类型定义 | 新建类型系统,只定义需要行为契约的对象 |
重建:地基先于楼层
重建的过程分了几个层次,每一层都先于上面那层存在。用数学的语言说:Axioms → Types → Theorems → Operations → Applications。每一层从下面那层推导出来,下面那层不感知上面那层。
 五层架构:每一层从下面那层推导出来
五层架构:每一层从下面那层推导出来
任何一条规则,必须能追溯到它属于哪一层、来自哪条公理。
新发现一(定理层): 最初重建时,公理层之上直接就是操作规程。规程是”从公理推导出来的执行标准”,这说法没错,但它把两件不同的事混在一起:已经被证明的结论,和这些结论的操作化。
在数学里,这两层是严格区分的:定理(Theorem)是重要的已证真语句;引理(Lemma)是帮助证明定理的小结论;推论(Corollary)是从定理直接得出的结果。我在公理层和操作规程层之间加了一个定理层,专门存放从公理推导出来的已证结论。结果是规程变得更干净——只管”怎么做”。理由在定理层里,每条规程都指向”来自哪个定理”。
新发现二(系统语言): 在建立定理层时,我开始用数学符号表达一些形式定义。符号比散文精确,消除了边界情况下可能产生的歧义。但符号在文章里读起来反人类。解决方案是内部规则层用符号作为推理的工作语言,输出层(文章、报告)用散文。判断标准只有一个:这个符号是否消除了散文无法消除的歧义?是则用,否则散文。
几个关键定义:
- Skill: 无状态的输入输出函数——给定相同输入,产生相同输出,不持有任何跨调用的隐藏状态
- Agent: 有状态的多阶段执行过程,可以调用 Skill,但不允许在同一上下文内嵌套调用另一个 Agent——避免状态污染
- Workflow: 有依赖约束的任务有向图,是任务拓扑,不是执行者
- Memory: 跨会话的持久状态,和 Context(会话内临时状态)严格区分——Memory 写入不可轻易撤销,适用可逆性公理
- Deliverable: 有血缘要求,每个出现在交付物里的数字或结论,必须能追溯到来源文件
不完备性边界: 最后,我加了一节不完备性边界——明确说清楚系统不覆盖哪些情况。哥德尔证明了任何足够强大的系统都有自己无法证明的真命题。这不是缺陷,是诚实。我的系统也一样。有些情况它处理不了,把它们列出来,遇到时不假装能处理,直接说清楚边界在哪。
重建结束时,系统有了根。但有一个问题悬在那里没有解决:品牌层放在哪里?
这五层架构里没有它的位置。而当我试图给它找位置时,我发现这不是一个 Agent 系统的问题——是一个关于数学、AI 与品牌三者关系的更深问题。
工具的边界:一个无法回避的妥协
整个重建过程是在 Claude Code 里完成的。
Claude Code 是一个 AI 原生的命令行工具,它把 AI 深度嵌入到开发环境里,可以读文件、写文件、执行命令、调用外部服务,整个项目目录都在它的视野里。这是它和普通聊天 AI 最本质的区别——它不只是回答问题,它在真实地操作你的工作环境。
但它有一个物理约束:配置文件必须放在 .claude/(工具目录)下面,否则系统无法自动加载。
这就产生了一个有趣的张力。我的公理文件、类型定义文件——这些是整个系统的地基,是一切规则的来源。但在文件系统里,它们被放在工具目录下面,看起来像是一个软件的配置文件。
文件结构说的是”这些是工具的参数”,但它们实际上是组织的大脑。
我没有办法完全解决这个矛盾——工具的约束是真实的,我不能为了哲学上的整洁而破坏系统的正常运行。但我做了两件事:
第一,在系统最显眼的文档里,写清楚这个约束是工具的要求,不是层级的声明。工具目录的位置是物理约束,不代表里面的内容在逻辑上从属于工具。
第二,在工具目录内部,严格按照逻辑层级来组织文件——公理层、类型层、定理层、操作规程层,各在其位。物理层级无法表达的东西,在内部结构里补偿回来。
同时,我在项目里建了一份对齐参考文档,记录 Claude Code 的执行模型。如果有一天工具换了,这份文档告诉新工具:这个系统的行为基准是什么,应该对齐什么。这是我对工具依赖风险的一个小小的对冲。
我做这件事,用的工具是 Claude Code,建的是一个营销 AI 工作系统。但工具和领域都不是这篇文章的重点。重点是那个认知上的转向。
我花了很长时间从执行走向思考——意识到不是代码出了问题,不是 Prompt 写得不够好,是系统缺乏内聚性。但更大的跨越,是弄清楚思考应该从哪里开始。
不是从经验中归纳规则——那样建出来的是补丁集合。而是先找到最底层的、真正独立的、互相不矛盾的第一原则,然后从那里向上,每一层严格从下面那层推导出来。
这是数学大厦两千多年沉淀下来的建造逻辑。欧几里得用五条公设推导整个几何学,不是因为他只知道五件事,而是因为他知道哪五件事是真正的地基——其他所有东西都可以从这五件事长出来。
把这个逻辑用在 Agent 系统上,结果是一个有根的系统——每一条规则都知道自己为什么存在,每一个组件都知道自己属于哪一层,每一次冲突都有机械可执行的解决路径。
混乱不会消失,但混乱有了出口。