从LLM到Agent Harness: 理解Agent的过去、现在和未来(一)

你可能听说过大家都在讲 AI,讲 Agent,讲智能体,也看到很多内容在推荐 Claude Code、Codex、Manus 这类产品。但真正追问下去,很多人其实并没有搞清楚:Agent 到底是什么?它和 Chatbot 有什么区别?为什么同样是大模型,有的只是陪你聊天,有的却能读文件、改代码、跑命令、持续完成任务?
其实我也是。如果你也和我一样对Agent本身充满好奇,那这组文章,为你而写。
我想用一组文章把这件事从头理清楚,也讲清楚。自己搞懂的同时,也帮助屏幕前的你搞懂。
我不会一上来就堆一堆定义,而是沿着 Agent 出现的真实路径往前推。
所以第一篇,我们先不急着讲工具、工作流和复杂工程Harness。我们先把 LLM 这个“大脑”本身讲清楚:它怎么生成文字,为什么 Prompt 能改变输出,为什么 Context 决定它当下能看到什么,以及为什么规模变大之后,会突然出现推理、写代码、翻译这些复杂能力。
只有先理解这一层,后面再讲 Chatbot、Prompt Engineer、Context Engineer,最后讲 Agent 和 Harness,才不会变成一堆时髦词的堆叠。
先说结论
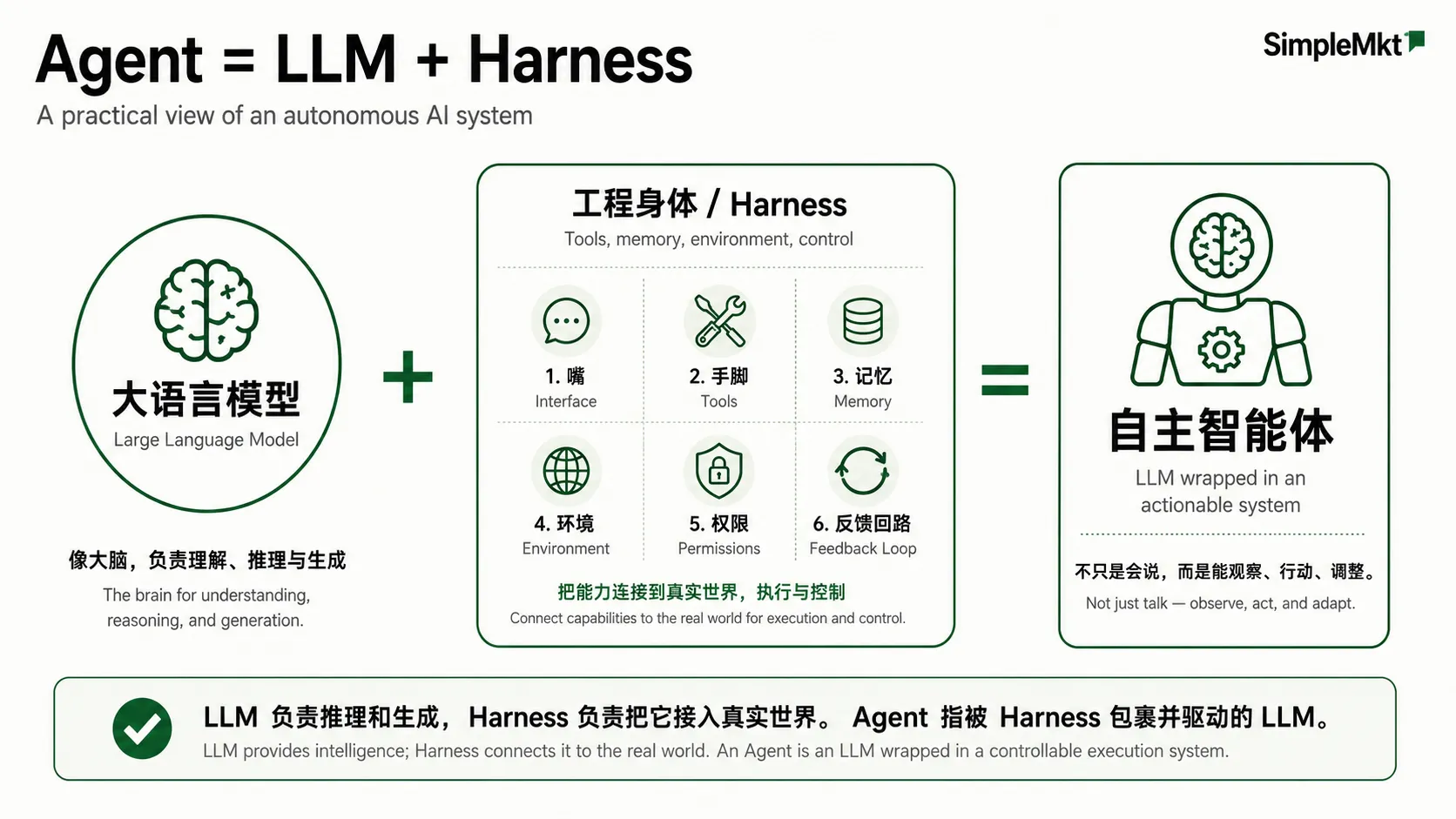
在工程实现上,我们目前可以先用一句话理解:Agent = LLM + Harness。
什么意思?我们一个个来理解。
LLM,也就是我们大名鼎鼎的大语言模型,它就像大脑。
它的核心工作就是猜下一个字最可能是什么。
就像你在手机输入法里打“今天天气真”,它自动跳出“好”“不错”一样,只不过它比输入法聪明几万倍。但这个大脑没有手脚,不能自己操作文件、运行命令,也不会在模型内部长期保存任务状态。
我们现在手头常用的很多 AI 产品,最底层都有一个 LLM。能对话,是因为产品把这个大脑接进了聊天界面,给它装了一张嘴,于是变成了 Chatbot(聊天机器人)。但如果只有聊天界面,它主要还是“你问一句,它答一句”。
Agent,指基于LLM的自主智能体,更多是在“大脑/嘴”之外加上手脚、允许调用的工具、记忆、干活的环境、权限和反馈回路等。
Agent不只是说,而是能做;不只是做一步,而是能观察结果后继续调整。
它更像是:一个 LLM 大脑,被装进了一套能行动、能观察、能记忆、能验证、能受控的工程身体里,能够实际操作你的文件、调用工具修改并观察结果,进一步调整。而这套工程身体的总称,目前业内称为 Harness。
Harness指LLM之外的嘴、手脚、工具、记忆、干活的环境等配置的综合体。
“Harness”在英文中意为“马具”,即套在马身上,让它能拉车、干活的一整套装备(缰绳、马鞍、马蹄铁等)。这个词用在 AI Agent 上,形象地比喻了它如何将“狂野”的模型能力,驯服和引导为可控、可靠的生产力。
这不是最严格定义,是一个业内普遍形成共识的好用好理解的视角。
LLM 负责推理和生成,Harness 负责把它接入真实世界。Agent指被Harness包裹着的LLM。
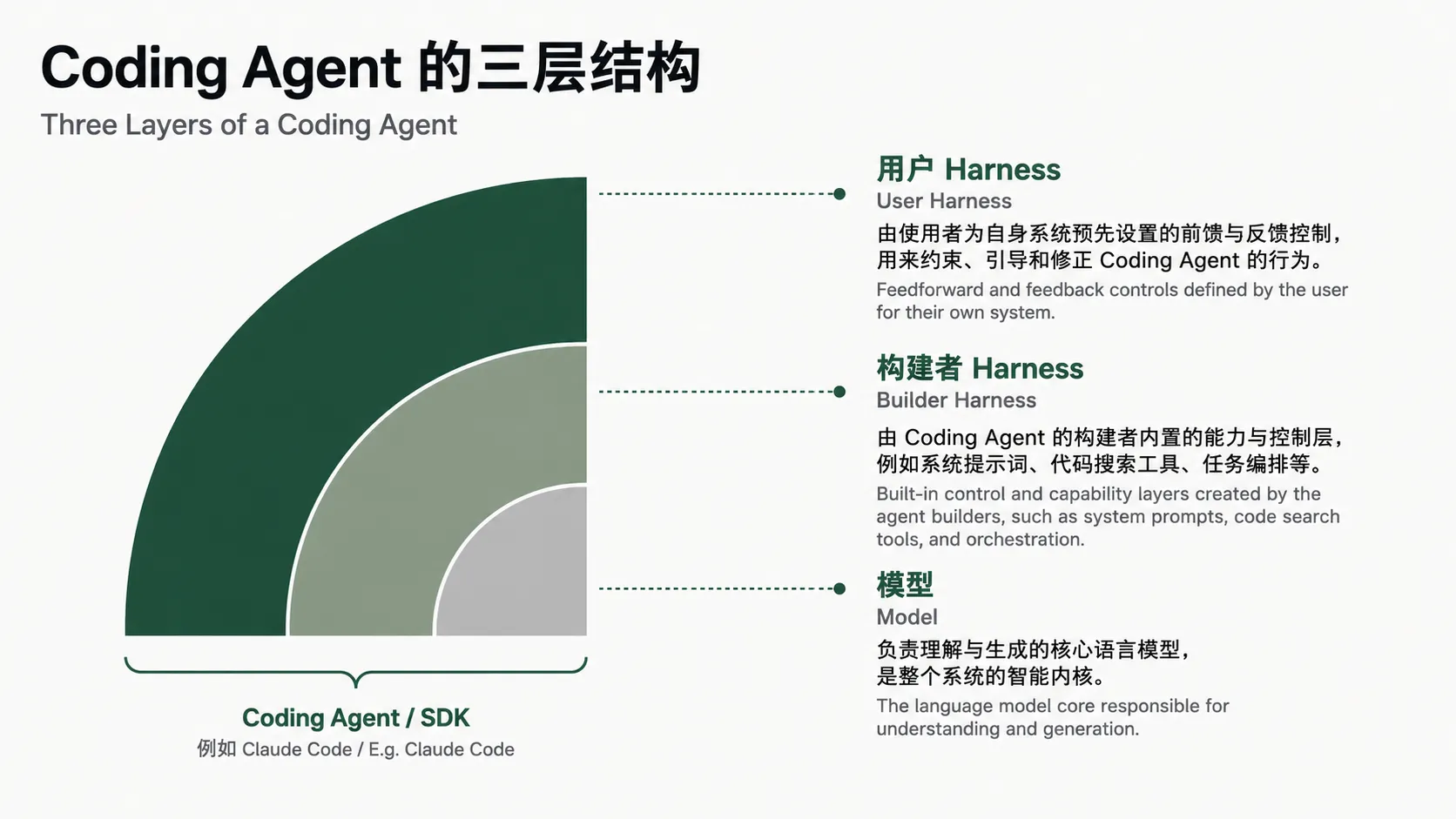
拿当下最核心的最主流也最强大的专门服务于代码生产的Coding Agent——Claude Code来举例,我们能清晰地看到Harness可以核心分为两层:
- Builder Harness:一层是偏系统底层的LLM执行用的Harness,叫Builder Harness,专门用于给LLM使用,比如Agent底层的定义(System Prompt)
- User Harness:一层是偏用户层的约束和规范Harness,专门辅助用户更好地去使用Coding Agent在某些规范下去解决某项具体的任务。
Claude Code 是 Anthropic 推出的 agentic coding tool。如果用本文的框架理解,它可以看成是把 Claude 这样的 LLM 接入代码仓库、终端、文件系统、工具调用和反馈循环的一套 Harness。也就是说,真正让它从“会说”变成“能做”的,不只是模型本身,而是模型外面这套工程身体。
LLM 到 Agent 之间,并不是直接跳过去的,Harness 也不是一蹴而就的。
为什么一个原本只会“接话”的语言模型,最后会一步步变成一个能读代码、改文件、跑命令、看报错、继续修复的 Agent?
这件事情得先回到 LLM(大语言模型) 本身说起。
最开始,AI只是一个“会接话的语言模型”
LLM 的机制其实是一个基于 Transformer 的自回归语言模型。
自回归,可以理解为它一个词一个词地接着往下生成。
总之,LLM的工作流程可以用一句话概括:
==给一段上文,计算下一个词(Token)的概率分布,然后按某种策略选一个词,把新词拼到上文末尾,再重复这个过程。==
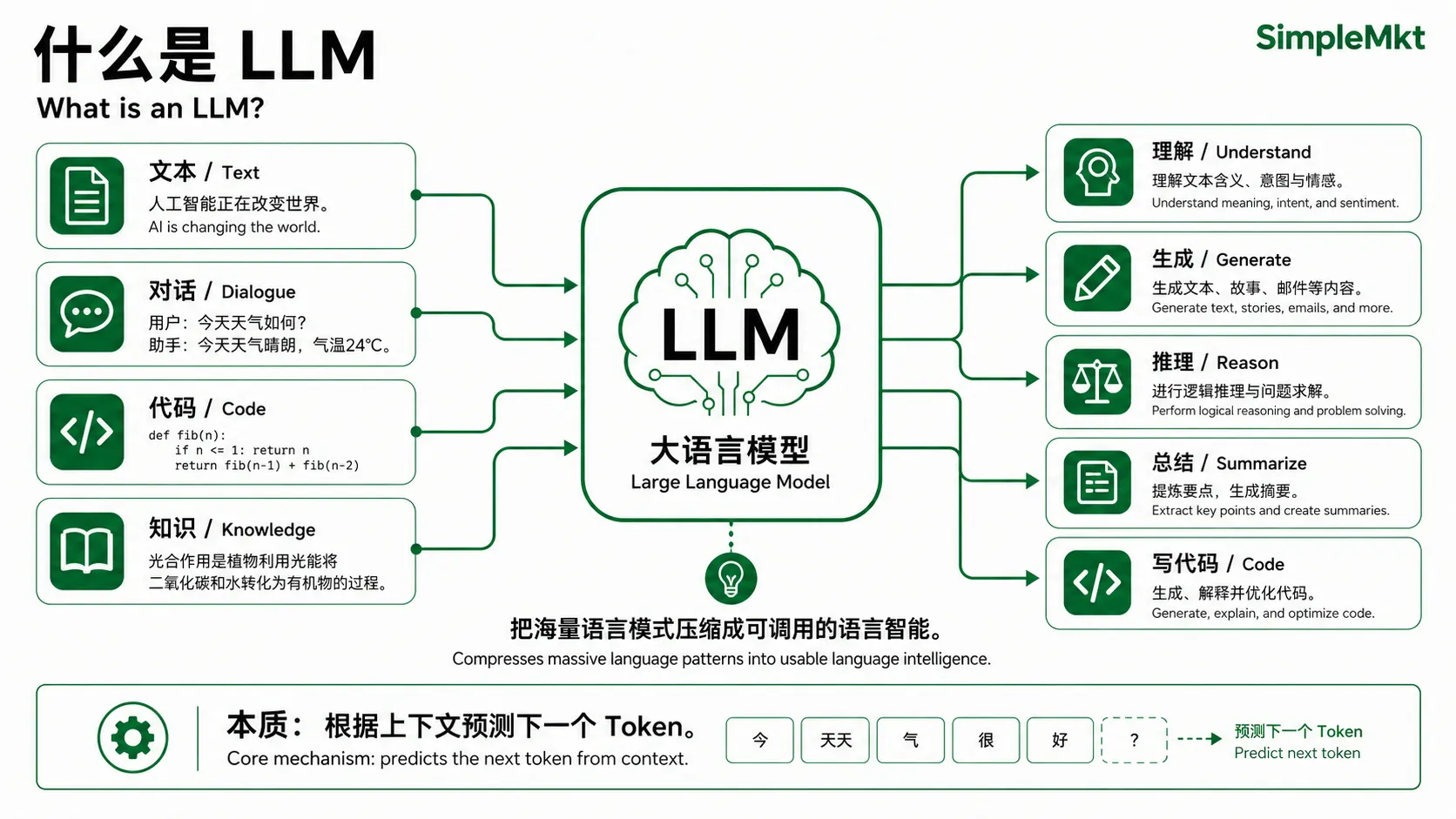
这个机制决定了关于 LLM 的一切。说白了,就叫“根据上文预测下一个词(Token)”。
关于LLM,有三个必须了解的基础概念:Token、Prompt和Context
Token(词元)
LLM本质上还是机器,无法直接处理原始文字,所以在真正处理文字之前,需要先将文本切成一个个最小的处理单元,叫做Token。
Token不是完整的词,而是“==子词==”或字符片段——中文里一个字、一个词 or 英文里一个单词或单词片段,都可能被拆成 token,比如“unbelievable”可能被切成 [“un”, “believe”, “able”]。
为什么不直接用现成的字母或词做Token? 核心是为了平衡“词汇量大小”和“序列长度”。
- 如果每个字都是一个 Token,那表示能力太弱。这会导致模型无法理解“多个字组成的固定意思”,只见树木,不见森林。比如,如果把 “like” 拆成 [“l”, “i”, “k”, “e”],模型就只能分别理解这四个字母。它完全无法知道这四个字母连在一起,到底是动词“喜欢”,还是介词“像”,还是名词“爱好”。字母本身几乎没有语义,模型相当于在看一堆没有意义的笔画,而不是一个有意义的词。以字母为单位,语义单元太小,模型要从零开始拼凑出几万个单词的含义,几乎不可能学好语言。
- 如果每个词都是独立 Token,这会导致模型的大脑(词表)必须记住无限多的词,词汇表会大到无法训练,直接撑爆。看看动词 “eat” 的家族,如果每个形态都算一个独立的新词放进词汇表:eat、eats、eating、ate、eaten、overeat、overeating、uneaten…光是 “eat” 一个动词,加上时态、语态、前缀后缀,就能衍生出几十个形态。英语里有上万个动词,如果每个词的全部变体都单独放进词汇表,词汇量会瞬间膨胀到几百万甚至上千万。更重要的是,模型会把 eat、eats、eating 当成三个完全不同的全新的东西,无法理解它们共享同一个核心动作,只是时态和语气不同。
这种“子词分词法”正好能复用词根,覆盖所有可能出现的文本,兼顾词汇量和Token长度。就像把 “unbelievable” 拆成 [“un”, “believe”, “able”],“eating” 拆成 [“eat”, “ing”]。这样,模型既能知道核心意思来自 eat 和 believe,又能通过 “ing”、“un”、“able” 这些共享积木来理解时态和语气。几千个积木,就能覆盖几十万个英文单词的全部变化。
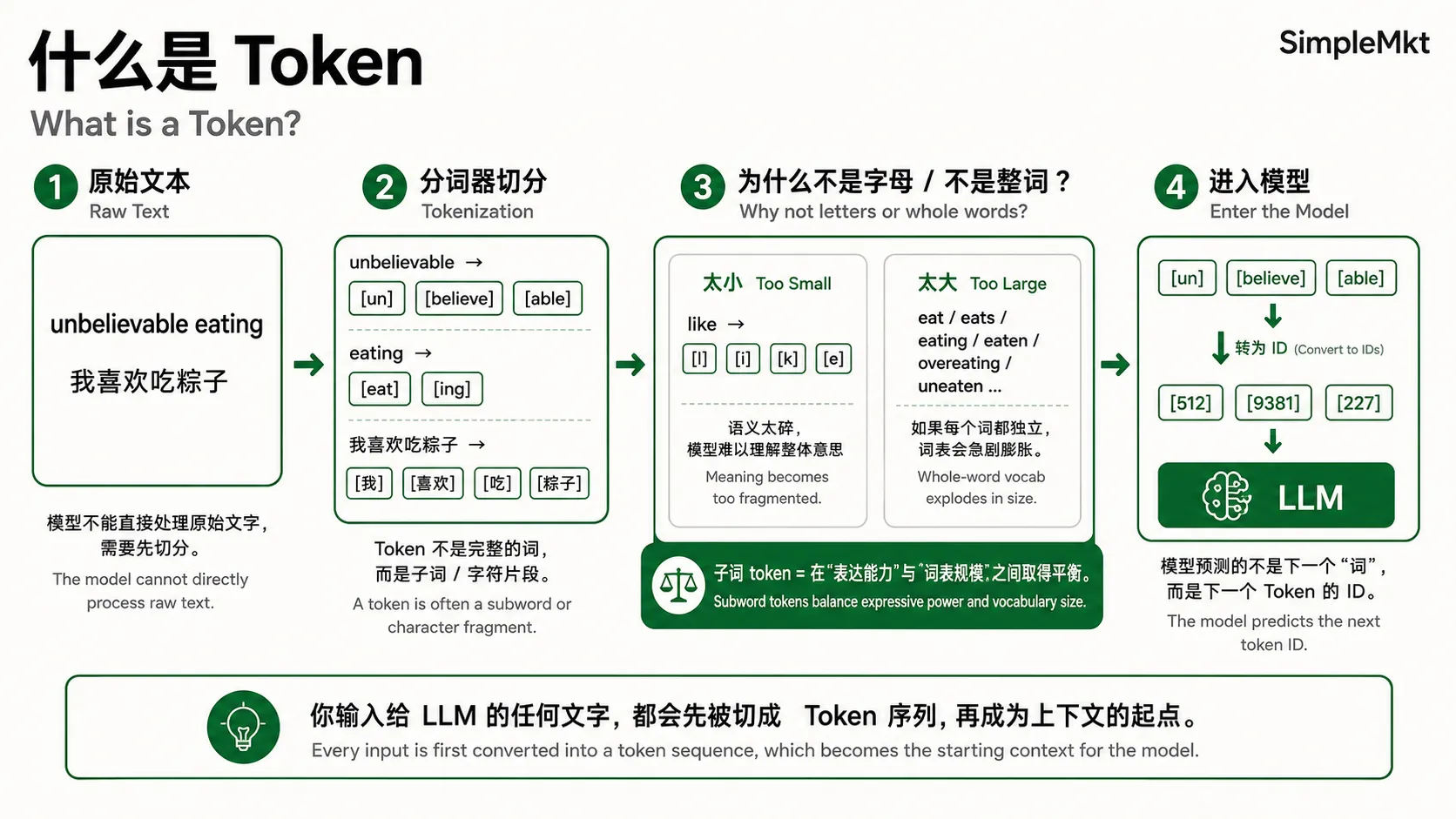
结果而言,就是你输入给LLM的任何话,都会被转换为一个 Token 序列,每个Token底层都有一个ID,就像一个字典上关于每个词的专属编号。模型预测下一个词,其实就是预测下一个Token的ID。
所以,当你输入一段文字,这段文字在被模型真正处理之前,它会先被分词器切成一串 Token(子词单元)。这串 Token 就成了上下文的起始部分。模型从这个起点开始,预测下一个 Token。
现在Token已经是公认的最基础的AI花销计量单位了,如何管理花在AI上的每一分钱,本质都是在分配 Token 预算。同时,”Token经济学”已经成型和爆火,大量厂商/个人在Token的倒买倒卖中试图在里面分一杯羹。不少厂商都推出了自己的Token套餐,其中不乏一些吃相比较难看的…
Prompt(提示词)
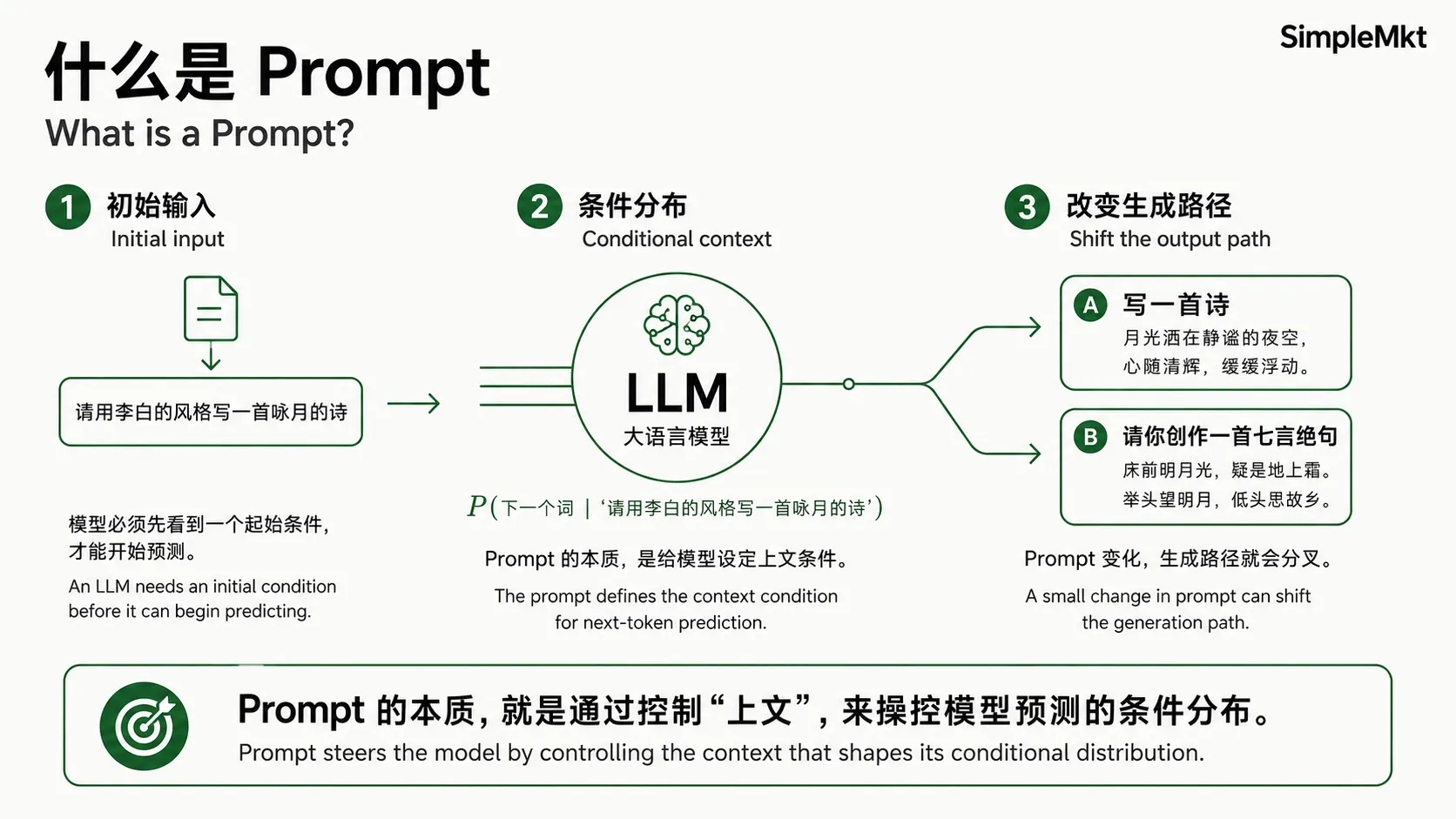
模型从一个如果上文是空的,它就寸步难行。因此LLM必须有一个初始输入,才能开始计算概率。
这个初始输入,就是 Prompt(提示词)。
从数学上来简单理解,Prompt就是你给模型提供的条件概率的前置条件。
模型看到 Prompt “请用李白的风格写一首咏月的诗”之后,它内部计算可以简单的理解为:
$P(\text{下一个词} \mid \text{“请用李白的风格写一首咏月的诗”})$
模型在训练时读过无数诗词、无数指令,它学到的模式是:当上文出现“李白”“风格”“诗”这些词时,后续出现的词大概率会是古诗体的、带有李白特色的词汇。
所以,Prompt 的本质,就是通过控制“上文”,来操控模型预测的“条件分布”。Prompt 稍有变化,条件就变了,输出的概率分布就可能发生显著偏移。
比如,说“写一首诗”和“请你创作一首七言绝句”,条件不同,生成的路径就分叉了。
这也为后来Prompt Engineering爆火埋下伏笔。
Context(上下文)
模型在生成每个新词(Token)时,都“回顾”它之前见过的所有内容。这个被回顾的整个上文(包括 Prompt、历史对话、自己的输出),就是 Context(上下文)。
除了训练时学到的参数化知识,裸模型在一次对话过程中没有真正的长期记忆,也不会天然连接网络。 当然,产品可以在模型外面接入记忆库、搜索、数据库和各种工具。但对模型本身来说,它当下能直接处理的,仍然是被放进上下文窗口里的内容。
而这个“回顾”的能力,正是由 Transformer 的关键的数学特性——自注意力机制(Self-Attention) 赋予的。
简单来理解,自注意力机制就是让句子中的每个词,都能和上下文里的所有其他词“打招呼”,并计算出一个“注意力权重”,来判断谁对自己最重要。
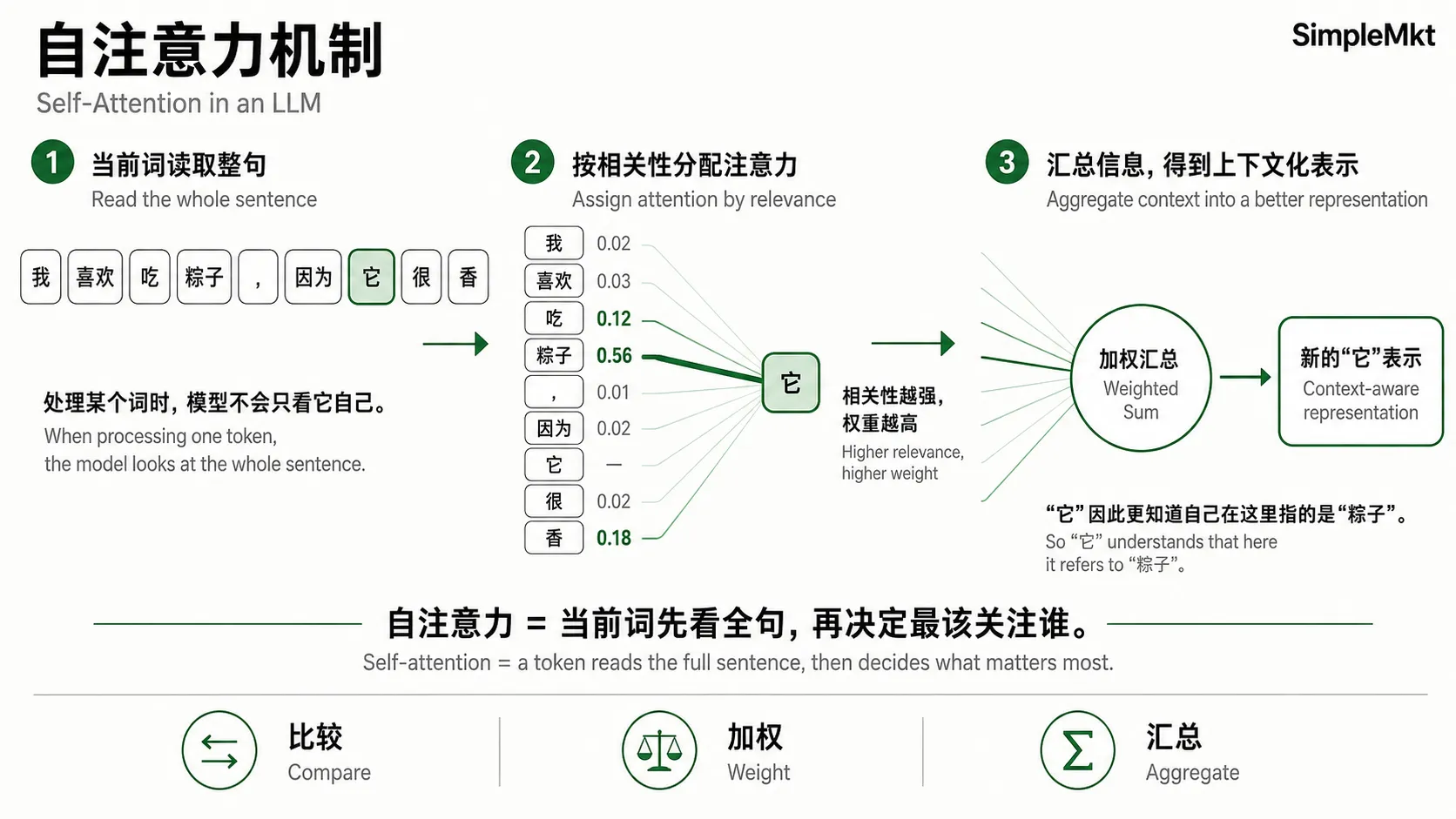
2017 年,Google 在论文《Attention Is All You Need》中提出的 Transformer 架构,彻底改变了自然语言处理的游戏规则。它抛弃了传统的循环神经网络(RNN),仅依靠注意力机制就实现了更强的性能和更高的训练效率。今天,几乎所有的大语言模型都建立在 Transformer 的基础之上。
那它能看无限长的上下文吗?答案是不能,这也是上下文约束(Context Constraint)的来源
因为标准的全量自注意力计算复杂度,和 LLM 底层的最小处理单元——Token 的数量有关。Token 越多,计算量会按平方级增长。
你可以理解为,在标准 Transformer 里,模型需要计算序列中每个位置与其他位置之间的关联。如果用 n 表示上下文中的 Token 数,那么这部分计算复杂度可以表示为 O(n²)。 现实中的长上下文模型会通过 KV cache、分块、稀疏注意力、检索和工程优化来缓解这个问题,但“上下文越长,成本和难度越高”这个基本约束没有消失。
所以系统必须划定一个最大长度,这就是上下文窗口(Context Window)。这个硬性的长度限制,也叫上下文约束(Context Constraint)。没有被放进窗口的内容,模型在当前这次推理里就看不见,如同从未存在。
下图展示了上下文窗口的演变趋势(示意图,由网页端 DeepSeek 梳理生成,非论文原图)
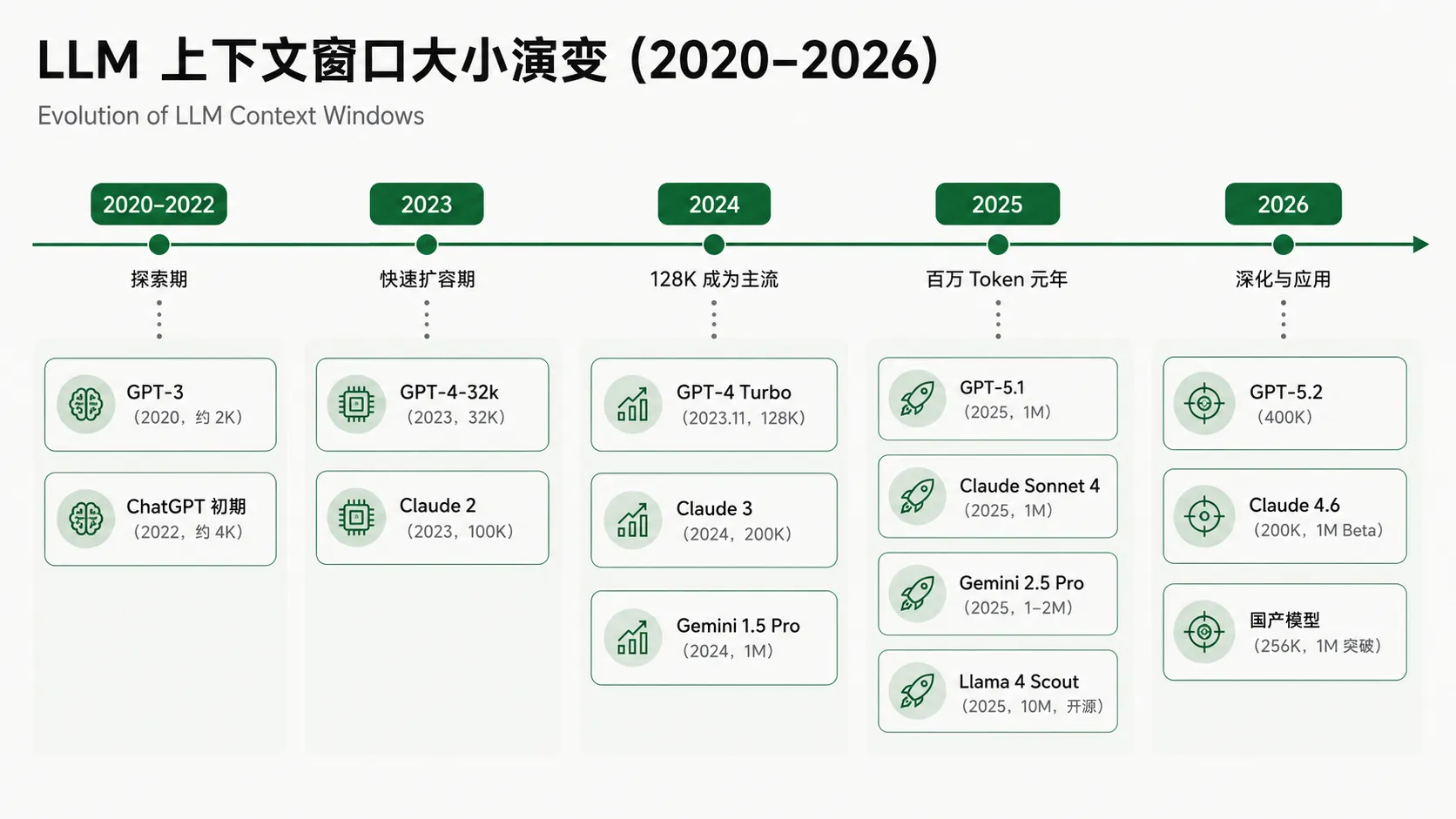
几点说明帮助你体会不同的上下文窗口的大小:
- 便利贴阶段 (≤4K):就像在巴掌大的纸上记事,聊几句就得擦掉重写,只够处理极短的问答。
- 短篇小说/说明书阶段 (32K):能把一份完整的产品手册或几十页合同摊开来看了,开始能处理有一定长度的文档。
- 长篇小说/项目文档阶段 (128K–200K):目前最主流的“工作台”,能装下《三体》第一部或一个中型项目的全部资料。这时候它已经能像个读过所有资料的同事一样和你协作。
- 全集/图书馆阶段 (1M–10M):桌子大到能把《三体》三部曲或者整个哈利·波特系列一次性摆满。百万级窗口让模型可以通览全集分析人物弧光,甚至读完整个代码仓库。千万级则相当于把一个专业领域的小型图书馆都放在了面前。
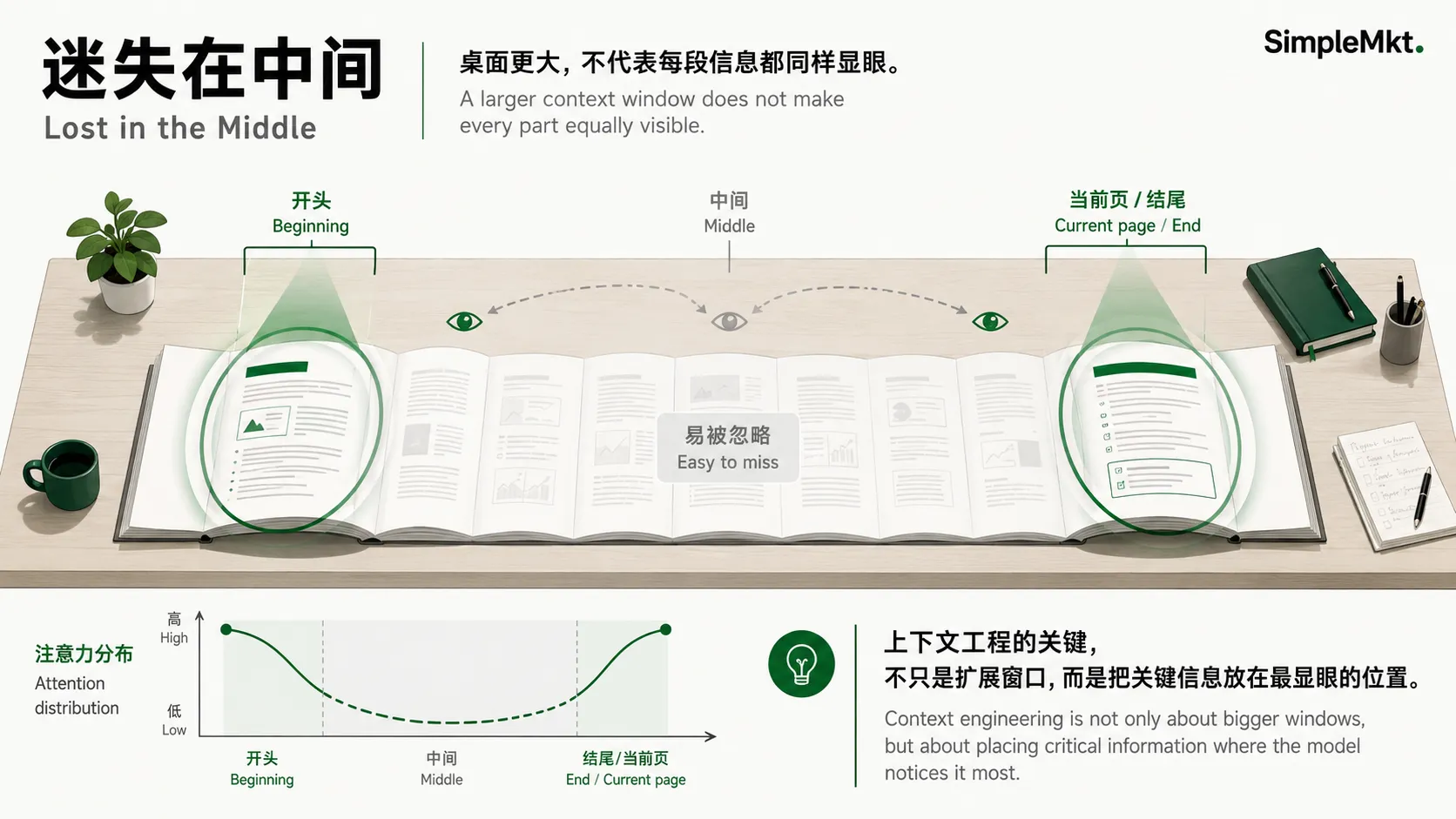
⚠️ 一个关键的“但是”:桌面大了,不代表每样东西都能被立刻找到
就像你把一本几百页的书摊开在巨大的工作台上,虽然所有内容都在你面前,但你的注意力天然会更多地集中在书的开头和正在读的那一页。中间那些被摊开的部分,你很容易一眼扫过而忽略掉细节。模型也是如此,即使上下文窗口变大了,但它依然容易对文档开头和结尾的信息抓得最准,对中间部分则容易“视而不见”。而这,又叫 “迷失在中间”(Lost in the Middle)效应,是我们不得不关注的关于LLM的重要缺陷之一。
所以,上下文工程的核心,并不仅仅是“换一张更大的桌子”,而是要学会如何在这张桌子上,把最重要的材料,永远摆放在模型最显眼的位置。这也是为什么,即便有了百万级 Token 的窗口,我们依然需要精心设计 Prompt 和检索策略,确保关键信息不被淹没在信息的汪洋大海里。
当“预测下一个Token”的AI突然开了窍
一个最开始只会玩“词语接龙”的统计模型,怎么就会写诗、翻译、写代码了?它真的理解了语言,还是只是在背诵?
答案有两个关键词:Scaling Law(规模法则) 和 Emergence (涌现)。
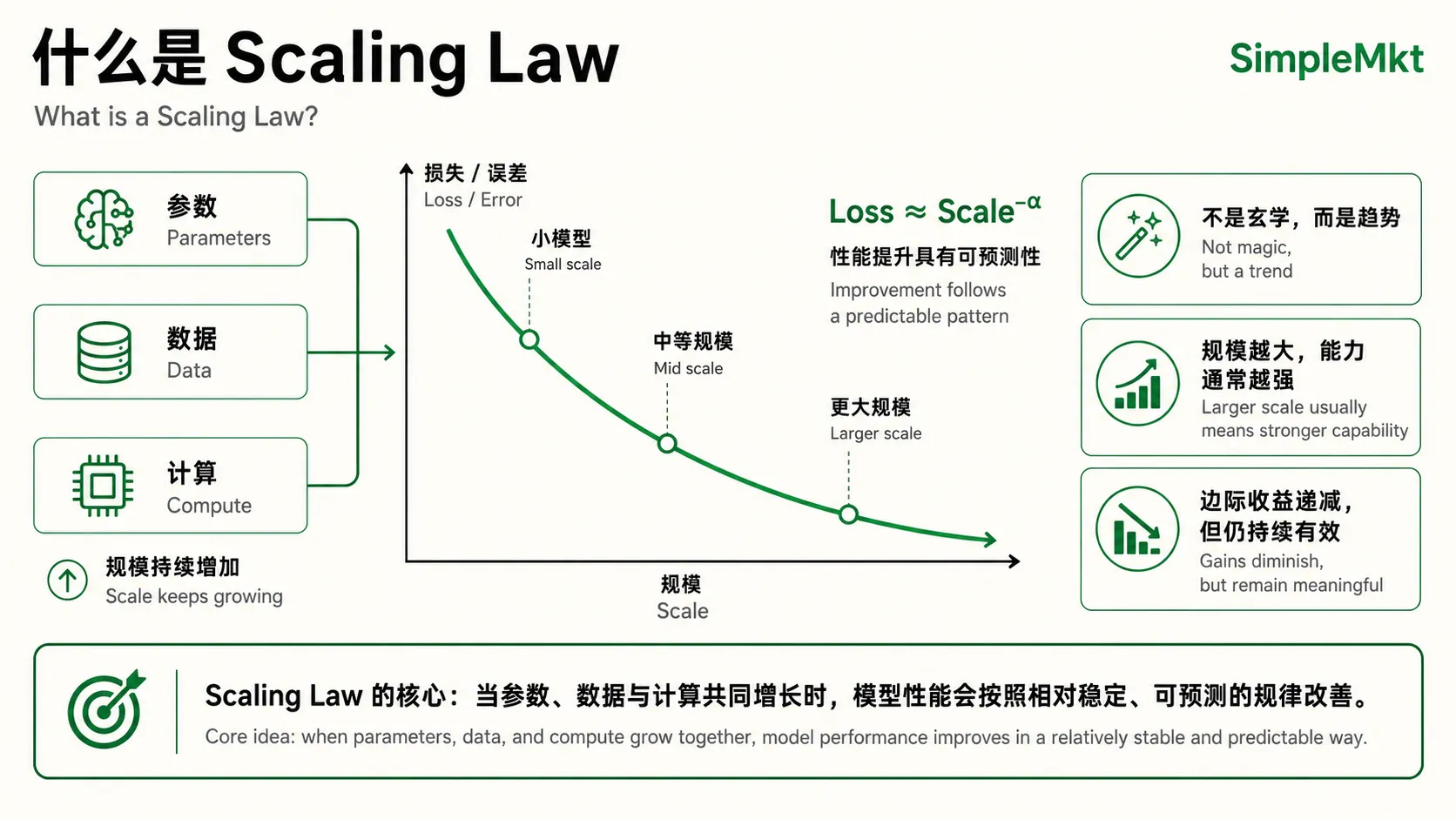
Scaling Law(规模法则):大力出奇迹的“科学依据”
后来成为 Anthropic 联合创始人的 Dario Amodei,早年曾在百度硅谷 AI 实验室参与语音识别相关工作,并与当时的百度首席科学家吴恩达(Andrew Ng)共事。他后来在访谈中回忆,正是在这类语音识别训练中,他开始注意到一个早期信号:==随着提供的数据变多、模型变大、训练时间变长,模型的性能表现出了显著且持续的提升==。这仍然只是访谈里的个人回忆,不是正式论文结论,但它能帮助我们理解 scaling law 思想出现的早期背景。
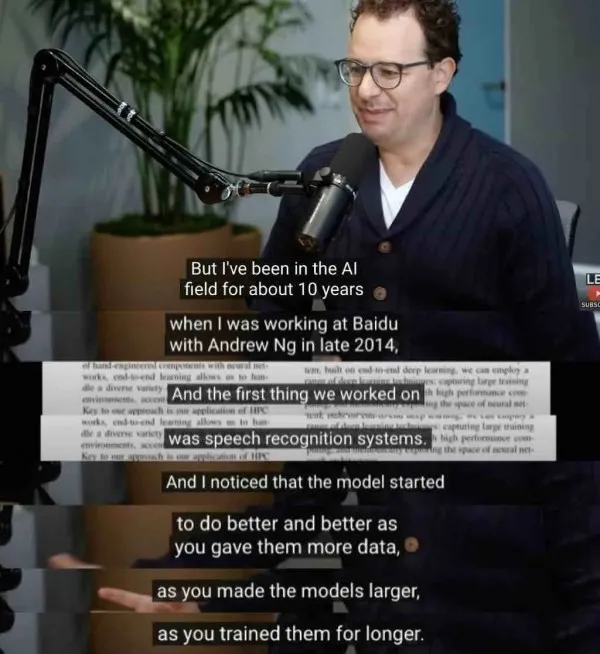
2017年,百度研究院发表了一项关键研究,题为 《Deep Learning Scaling is Predictable, Empirically》(深度学习的规模效应是可预测的,基于经验)。这项研究通过实验证明:
深度学习模型的泛化能力,与模型大小、训练数据量等规模因素之间,呈现出一种可预测的幂律关系。
这可以说是“Scaling Law”概念在产业界最早、最明确的实证探索之一,为后续的理论化工作铺平了道路。
故事的高潮发生在 2020 年的 OpenAI。此时,Dario Amodei 已从百度加入 OpenAI 并担任研究副总裁。或许受当年的那个灵感火花驱动。OpenAI 的研究者训练了几十个不同规模的模型,然后把这些模型的性能画在了一张对数坐标图上。
结果,一条平滑的直线出现了:

于是,2020 年 1 月,OpenAI 发布了那篇具有划时代意义的论文 《Scaling Laws for Neural Language Models》。论文精准地证明了:
语言模型的最终性能,与计算量(投入的算力)、数据集大小(训练数据量)和模型参数量这三者之间,存在着跨越 7 个数量级的、极其稳定的幂律关系。
换句话说,他们用相对严格的数理方式,证明了一条“炼金术公式”:你投入多少资源,模型就会可预测地变好多少。
它不再只是忽高忽低的玄学,而是出现了可以被经验预测的规律。
这条规律,后来被命名为大名鼎鼎的Scaling Law(规模法则)。
从此,“Scaling Law”从一个模糊的直觉和经验法则,正式成为指导整个大语言模型行业发展的第一性原理与“军备竞赛”的理论基石。而 Dario Amodei 本人,也正是带着对这一核心原理的深刻信仰,在不久后离开 OpenAI,创立了 Anthropic。
这给整个行业吃了一颗定心丸。它意味着,在相当大的范围内,持续往模型里“堆料”——更多的参数、更多的数据、更多的 GPU——模型性能会呈现可预测的提升趋势。这不等于“只要堆料就必然变好”,但它足以把大模型训练从纯粹赌博,推进到一套更有依据的工程投入模型。LLM 军备竞赛的大门,由此打开。
题外话:Scaling Law到头了吗?
从AI爆发以来这个问题一直在被争论,经常能看到关于AI的Scaling Law的边际效用递减的资讯,但这个可能只有最核心做模型研究的那批人才说的清楚。
前段时间,张小珺对姚顺宇的采访《独家对话姚顺宇:请允许我小疯一下》中,姚顺宇给出了一组基于一线模型研究视角的判断。注意,这是研究者访谈观点,不是论文结论:
- 理论上,未见顶:作为“经验定律”的 Scaling Law 本身依然有效,潜力巨大。
- 实践上,多 Bug:所谓“撞墙”,大多是执行层面的问题,掩盖了真实的进步。
- 未来上,靠系统:“个人英雄”红利消失,未来 AI 的突破将取决于能否构建一个“靠谱”的集体系统,通过出色的工程去逼近理论的极限。


姚顺宇有理论物理学背景,曾在 Anthropic 工作,后来加入 Google DeepMind。他对 Scaling Law 的判断,代表了模型一线研究者中一种很重要的看法:规模并没有简单失效,真正的问题在于工程系统能不能把理论潜力逼出来。
类似的判断,也不断出现在模型公司负责人和研究者的公开表达里:他们并不认为 Scaling Law 已经简单撞墙。更准确地说,行业正在从“只靠预训练规模扩张”,进入“预训练、后训练、推理时计算、合成数据和 Agent 系统一起扩张”的新阶段。

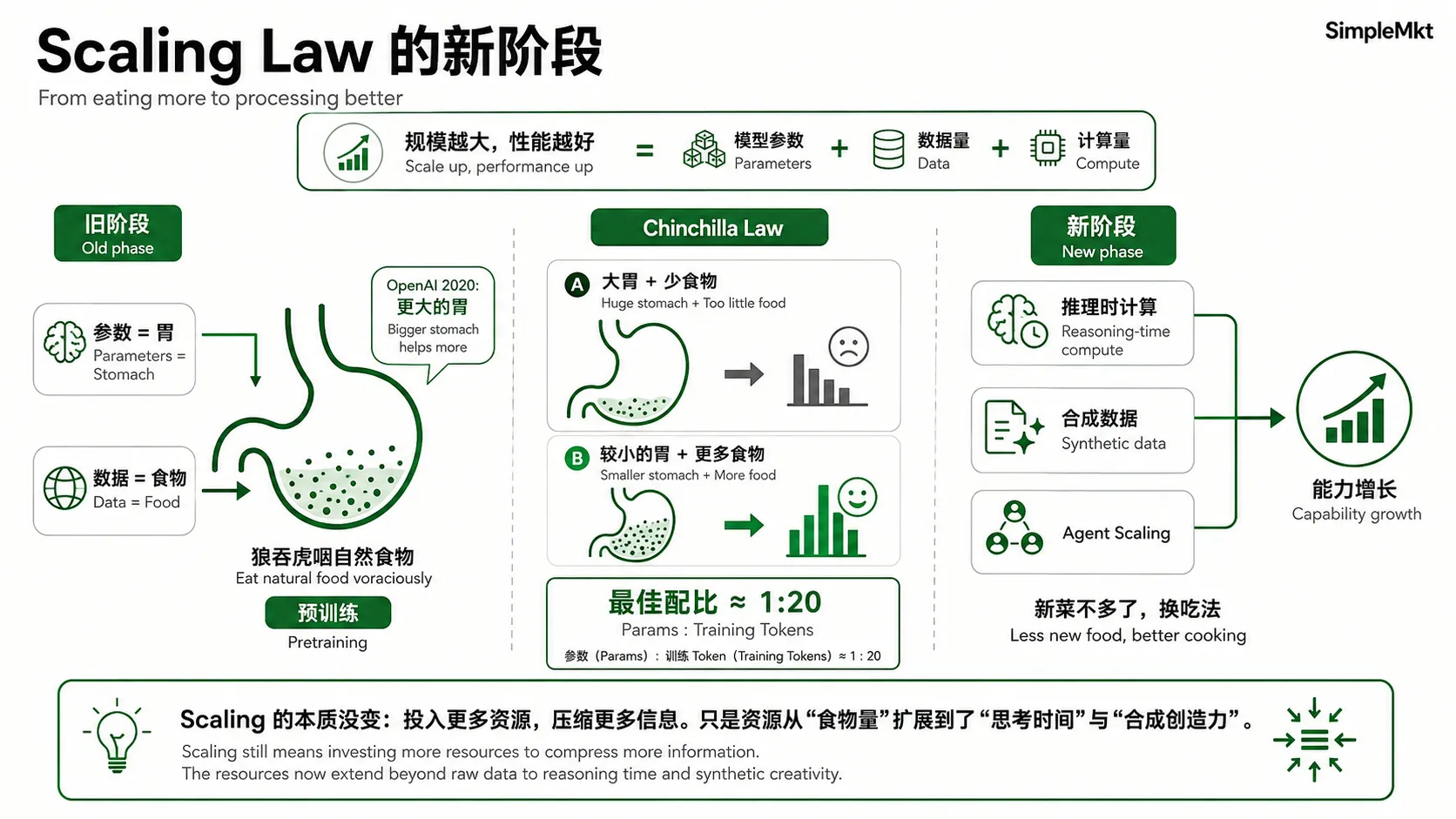
如果把Scaling Law比作一个巨大的、自动化的“超级胃”,它的终极目标就是吃遍并消化全世界的食物(互联网上的数据),然后变得超级强壮聪明。那么当下,地球上能找到的“自然食物”(人类互联网公开数据),大概率已经被AI吃得差不多了。虽然Scaling Law大概率没有到头,但边际效用递减的感受却实实在在地被大家感知到了。
在Scaling Law的研究中,扩大规模主要通过增加模型参数量(“胃”)和增加训练数据量(“食物”)这两个方向进行。
OpenAI 在 2020 年提出的 Scaling Law,让行业更有信心继续扩大参数、数据和算力规模。这种思路直接推动了 GPT-3(1750 亿参数)这样的超大模型出现。
2022 年 Google DeepMind 的“Chinchilla”研究带来了颠覆性观点。他们发现,在一定的“算力预算”下,许多模型其实是“营养不良”的——胃很大,但吃的食物不够多。“胃容量”和“食物数量”应该等比增加,才能达到最佳性价比。
例如,他们的 Chinchilla 模型(700 亿参数)虽比 Gopher(2800 亿参数)小得多,但因“吃”了 4 倍多的数据,最终表现反而更优。
“Chinchilla Law” 是 Chinchilla 研究的核心,它给出了一个具体的“营养配方”建议,即模型参数与训练 Token 数(食物量)的理想比例约为 1:20,以特定算力预算实现效果最大化。
反过来也可以说,很多细分的新吃法刚刚开始——既然吃新菜的收益在下滑,那就换烹饪方式。
- 原先:狼吞虎咽(预训练,比拼吃得多)。
- 现在:开始细嚼慢咽,反复琢磨。同一道菜,花十倍时间去研究它的分子结构(推理时计算),或者让模型自己给自己做新菜(合成数据),或者派出几个助手一起去满世界找菜谱(Agent Scaling)。
所以,不是说Scaling Law”吃饭长力气“这个根本规律失效了,而是从“狼吞虎咽自然食物”这个旧阶段转向“精细加工、人工合成、循环再利用”的新阶段。Scaling 的本质——投入更多资源去压缩更多信息——从未改变,只是投入的资源,从单纯的“食物量”,变成了“思考的时间”和“合成的创造力”。
Emergence (涌现):当量变终于引发质变
Scaling Law除了解释了大模型“性能稳定变好”,也给模型的能力突然跃迁打下了重要的基础。
当模型的参数从几千万膨胀到百亿、千亿级别时,研究者观察到了一些奇怪的现象。某些在小模型上完全不存在的“智能行为”,在超大模型上自己就冒出来了。模型没有为这些行为被专门训练过,训练目标始终只有简单的“预测下一个 Token”。但它们就是出现了,就像水在 100 摄氏度时突然沸腾一样。
研究者们借用了复杂科学里的一个古老词汇来形容它——涌现。涌现, 就是量变引起质变。
涌现能力,指的是在小规模模型中不存在,但在大规模模型中存在的能力。
“涌现”(Emergence)这个概念并非 AI 领域独有,它根植于复杂系统科学。其核心思想正如诺贝尔物理学奖得主菲利普·安德森(P.W. Anderson)的名言——“多者异也”(More is different)所揭示:当系统组件以简单的规则交互,规模达到一定程度后,整体会突然表现出全新的、无法从个体行为直接预测的宏观属性。
涌现为何会发生?
其实目前关于大语言模型(LLM)“涌现”原理的学术研究,正处于一个蓬勃发展但尚无统一严格证明的阶段,一些事情专业的学者也无法说清楚。因为本质上这是一种复杂系统的现象的解释性的证明,难度很大。但也并不妨碍我们先了解和理解这个现象。
一些来自自然界的类比可能有助于理解:
- 单个水分子(H₂O)既没有“湿”的感觉,也没有“流动”的特性。但当无数水分子聚集在一起时,“湿润”和“流动”这些全新的宏观属性便涌现了出来。
- 单个蚂蚁的行为极其简单,但当蚁群突破一定规模,便会涌现出“种植真菌”、“饲养蚜虫”等复杂的农业文明行为——而解剖任何一只蚂蚁,你都找不到负责这些行为的基因。
同样,当神经网络拥有足够多的“蚂蚁”(参数),它们之间会产生全新的协作方式,让智慧悄然诞生。
涌现什么时候被发现的:GPT-3 与“规模即能力”
2020 年,OpenAI 发表了具有里程碑意义的论文《Language Models are Few-Shot Learners》,介绍了他们训练的拥有 1750 亿参数的语言模型——GPT-3。
这篇论文的核心贡献,不在于提出了全新的模型架构,而在于证明了一个惊人的事实:“规模即能力” 。当 Transformer 的参数规模膨胀到 1750 亿这个此前难以想象的量级时,一种前所未有的能力解锁了:
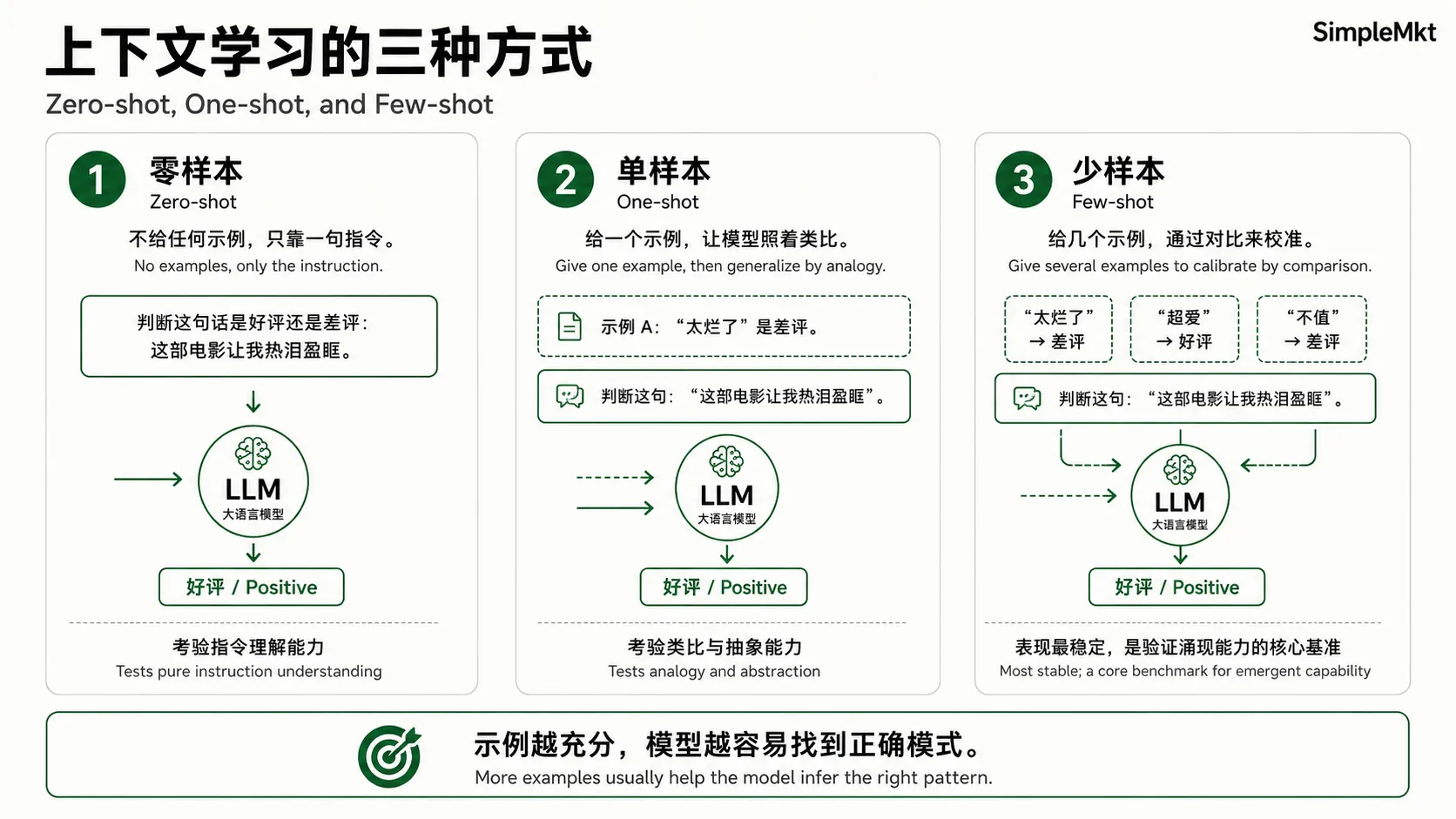
模型无需针对任何下游任务进行微调(即不需要更新任何参数),仅通过在输入中提供寥寥几个示例(few-shot prompting),就能在翻译、问答、算术、单词重组等数十个 NLP 任务中实现与当时最优模型相当、甚至超越的性能。
这种在 GPT-2 时期初现雏形的能力,在 GPT-3 上变得强大和稳定。后来研究者常把这种能力称为 “上下文学习”(In-Context Learning)。比如,你想让它把英文翻译成法文,不用重新训练模型,直接在输入里写:
英文: Hello → 法文: Bonjour
英文: Thank you → 法文: Merci
英文: Good morning → 法文:模型看到这两个示例,立刻识别出这是一种“翻译模式”,然后正确地接上 Bonjour。
GPT-3 论文的核心贡献并非“发明”了上下文学习,而是在大规模上系统展示了这种能力的强度和通用性。 它开创了“预训练 + 提示词”的全新 AI 范式,让 AI 从“需要专属训练”的专用工具,变成了“能通过上下文完成新任务”的通用助手。
2019年的 GPT-2 论文其实已经展示了早期迹象——模型无需微调即可在 zero-shot 设置下执行一些下游任务,这也被认为是上下文学习的雏形。到 GPT-3,OpenAI 将模型规模推至 1750 亿参数,这种能力才变得更强、更稳定、更通用。
涌现的正式确立:Google 的“涌现”大规模实证
GPT-3 让世界看到了这种现象,但真正让“涌现”概念在大模型领域正式确立的,是 Google 团队在 2022 年发表的论文 《Emergent Abilities of Large Language Models》 。
这项研究考察了以 GPT-3、Gopher、LaMDA 为代表的一系列语言模型,发现语言模型的表现并非随着模型规模增加而线性增长,而是存在临界点——只有当模型大到超过特定的临界值,才会涌现出较小的模型不具备的能力。这是涌现现象的首次大规模系统实证。
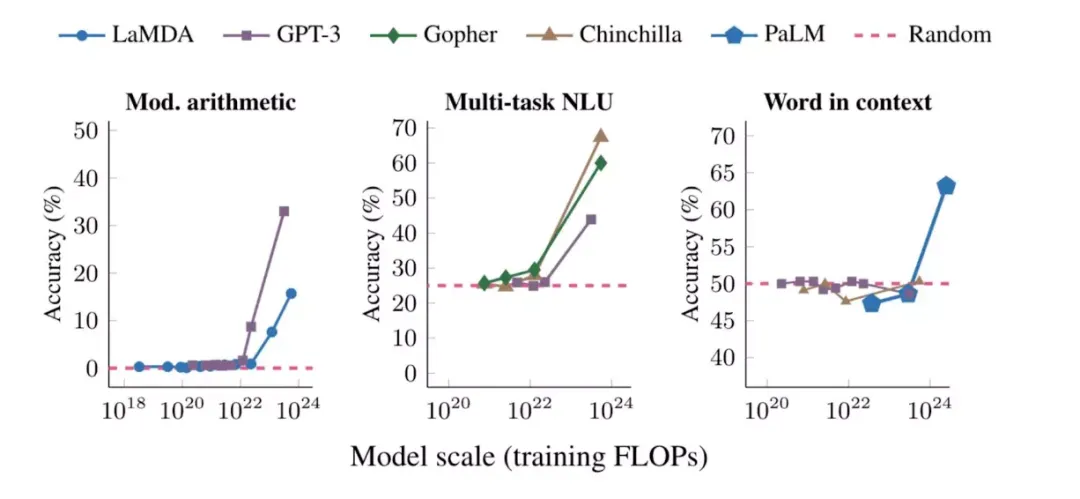
上图显示了涌现能力的三个例子:运算能力、参加大学水平的考试(多任务 NLU),以及识别一个词的语境含义的能力。在每种情况下,语言模型最初表现很差,并且与模型大小基本无关,但当模型规模达到一个阈值时,语言模型的表现能力突然提高。
涌现能力很难简单通过外推小模型的表现来预测,这意味着继续扩大规模可能会进一步扩展模型的能力边界。论文中的一些任务显示,能力跃迁大致出现在特定规模区间,例如接近 10²² 次训练浮点运算的量级附近。但这不是一个所有能力共享的统一开关,不同任务、数据和评估方式都会影响它出现的位置。
那大模型都涌现了什么能力呢?
除了上下文学习,后续研究者还整理过大量被观察到的涌现能力,其中包括逐步推理的“思维链”(Chain-of-Thought)、多步算术、跨语言翻译、代码生成、多任务语言理解(MMLU)、心智理论、自我校准等。
1. 思维链 (Chain-of-Thought, CoT):学会“一步步思考”
这可以说是最著名的涌现能力。小模型像是一个急于给出答案的毛躁孩子,你问它“小明有 5 个苹果,给了小红 2 个,又买了 3 个,还剩几个?”,它可能会直接瞎猜一个答案。但大模型却仿佛内在产生了一个声音:“让我们一步一步思考”。它会自己写出步骤:5 - 2 = 3;3 + 3 = 6。最后给出答案 6。
2. 算术推理 (Arithmetic Reasoning):从“数数”到“计算”
很小的模型可能只能勉强做“1+1=2”。但模型一旦涌现了推理能力,它能突然处理三位数、四位数的加减乘除,甚至混合运算。这不是因为它背下了所有的算术题(因为题目是无限的),而是它涌现出了对“十进制”、“进位”、“运算规则”的抽象理解。
3. 代码生成与理解 (Code Generation):获得“编程”超能力
你把一段自然语言描述“写一个 Python 程序,把列表里的所有偶数挑出来”,喂给大模型,它能直接吐出可运行的代码。它甚至能理解你给的一大段有 bug 的代码,并指出错误在哪。
编程语言是一种极度严谨、逻辑嵌套复杂的形式语言。之前小模型只能模仿代码的“样子”,写出来的东西大概率语法错误或逻辑全无。而大模型涌现出了对算法、逻辑控制流(如循环、条件判断) 的深层表征能力,它“懂”了程序是一个按步骤执行的逻辑机器。
4. 多语言翻译 (Multilingual Translation):突然无师自通的“通晓各国语言”
即使训练数据里并没有将“中文-斯瓦希里语”的平行对照句子喂给模型,当大模型学会了足够多的中、英文,又学会了一些英文-斯瓦希里语的对照后,它会突然涌现出一种能力:直接把中文翻译成斯瓦希里语。
这是因为它在海量多语言训练中,无监督地构建了一个“语义中间层”。不管什么语言,描述“开心”、“走路”、“太阳”的核心语义在它的高维空间里被拉到了相近的位置。一旦模型大到能清晰构建这个“语义巴别塔”,跨语种翻译就自然涌现了。
5. 多任务语言理解 (MMLU):文科、理科、医学、法律……门门通
这是测试 LLM 能力的一个“超级大考卷”,涵盖 57 个学科:从基础数学、物理,到历史、法律、医学、伦理道德。小模型做这种题,得分几乎等于瞎蒙。但一旦模型涌现,它可以像一个博览群书的通才,在所有学科上都展现出相当高的正确率。
这说明模型涌现出了强大的常识与推理能力。它不是在某个科目里死记硬背,而是学会了“如何根据上下文,调用相关的背景知识来推理出最合理的选项”。
涌现是连接“量变”与“质变”的桥梁。它从规模法则中诞生,是大规模训练的“意外之喜”;它以能力突变为标志,彻底改变了 AI 范式;它也引发了“是质变还是错觉”的学术思辨,推动着更深层次的研究。
但这些涌现出来的能力,真的是我们人类想象中的那种“智慧”吗?
更谨慎的说法是:LLM 所展现的,首先是可观察、可评估的“能力涌现” (Emergent Abilities),而不是已经被严格证明的“智能涌现” (Emergent Intelligence)。这两个词不能混用。
这并不妨碍我们先欣赏和利用这个现象。正如 18 世纪的物理学家们虽未完全理解热力学的微观本质,却已能用蒸汽机改变世界——我们今天对大模型的驾驭,正处在相似的时刻。
尽管涌现的底层原理尚未完全探明,但它已经催生了一种全新的应用范式:Prompt 本身,成了给模型“编程”的接口。
这意味着,使用 AI 的门槛从“你得懂模型训练”骤然降到了“你得会组织语言”。正是从这里开始,大模型从实验室走向了每一个人,而 Prompt Engineering 的爆发,以及我们熟悉的 ChatGPT 这样的聊天机器人,也由此埋下了火种。
所以这一篇,实际上我们是先把 LLM 这个“大脑”拆开看了一遍,打好一些基础的相对的底层理解。
LLM最底层的工作方式,是根据已有上文预测下一个 Token。Token 决定了它如何处理语言,Prompt 决定了它从哪里开始生成,Context 决定了它当下能看见什么。而 Scaling Law 和 Emergence 解释了另一件关键的事:为什么一个原本只是“接话”的模型,规模变大之后,突然开始表现出推理、翻译、写代码、上下文学习这些复杂能力。
AI真正的爆发是在后来,这个大脑被放进聊天窗口里,变成了 Chatbot;人们发现问法不同,输出差别巨大,于是 Prompt Engineering 火了起来;再往后,大家又发现真正影响模型表现的,不只是一句 Prompt,而是整个 Context 如何组织:资料、历史、规则、工具结果、外部知识,哪些该给,哪些不该给,怎么放进去。
而当 LLM 不只是回答问题,而是开始调用工具、观察结果、继续行动时,真正的 Agent 问题才出现。
下一篇,我们就从 Chatbot、Prompt Engineering 和 Context Engineering 讲起,继续看这个会说话的大脑,是怎样一步步走向能行动的 Agent。
为什么聊想要好好聊Agent的诞生历史?
在AI爆火以来,我长期大量地使用,也曾热血地发过一些内容,作为一个非技术人员,在使用的过程深深地感受到了一件事情:
AI没有想象的那么简单。
不是你天天用就叫会用AI,也不是你每天嘴上说着蒸馏、skill就叫懂了AI,这些都只是冰山一角,很多人连prompt都讲不明白,就自称专家、AI Builder,开源自己的skill什么的(你们开源的东西真的有自媒体以外的价值吗?)。
不论如何,作为一个非这个行业的人,我不想做这种打嘴炮的自媒体营销号的事情,更想能够以一个更好的姿态或身份参与和加入到这个行业中,也希望自己能更好地用好AI去做一些事情,还希望这个过程能帮助自己构建一些影响力的同时也帮助这个行业以外的,和我一样的人,对AI有更加深的理解,降低被割韭菜的概率。
那势必要求对底层的原理能有更多的理解,所以回过头来好好地补上一些历史和知识,还是很有必要的。
理解很多基本知识,你会发现很多使用AI的技巧根本没有意义,因为核心原理就是那些。
主笔:炼金术士周冷清 AI 辅助:DeepSeek Chatbot、ChatGPT Chatbot、Codex Agent 辅助内容:资料整理、结构讨论、事实核查、文本润色、配图生成