从LLM到Agent Harness:理解Agent的过去、现在和未来(二)
上一篇我们说了一些重要的关于LLM的基础的知识,比如:
- LLM它最底层只会做一件事——根据上文预测下一个 Token。
- Scaling Law 解释了为什么模型越大,能力往往越强;
- Emergence 解释了为什么一个原本只会“接话”的机器,会突然表现出写代码、做推理、跨语种翻译、总结文章这些复杂能力。
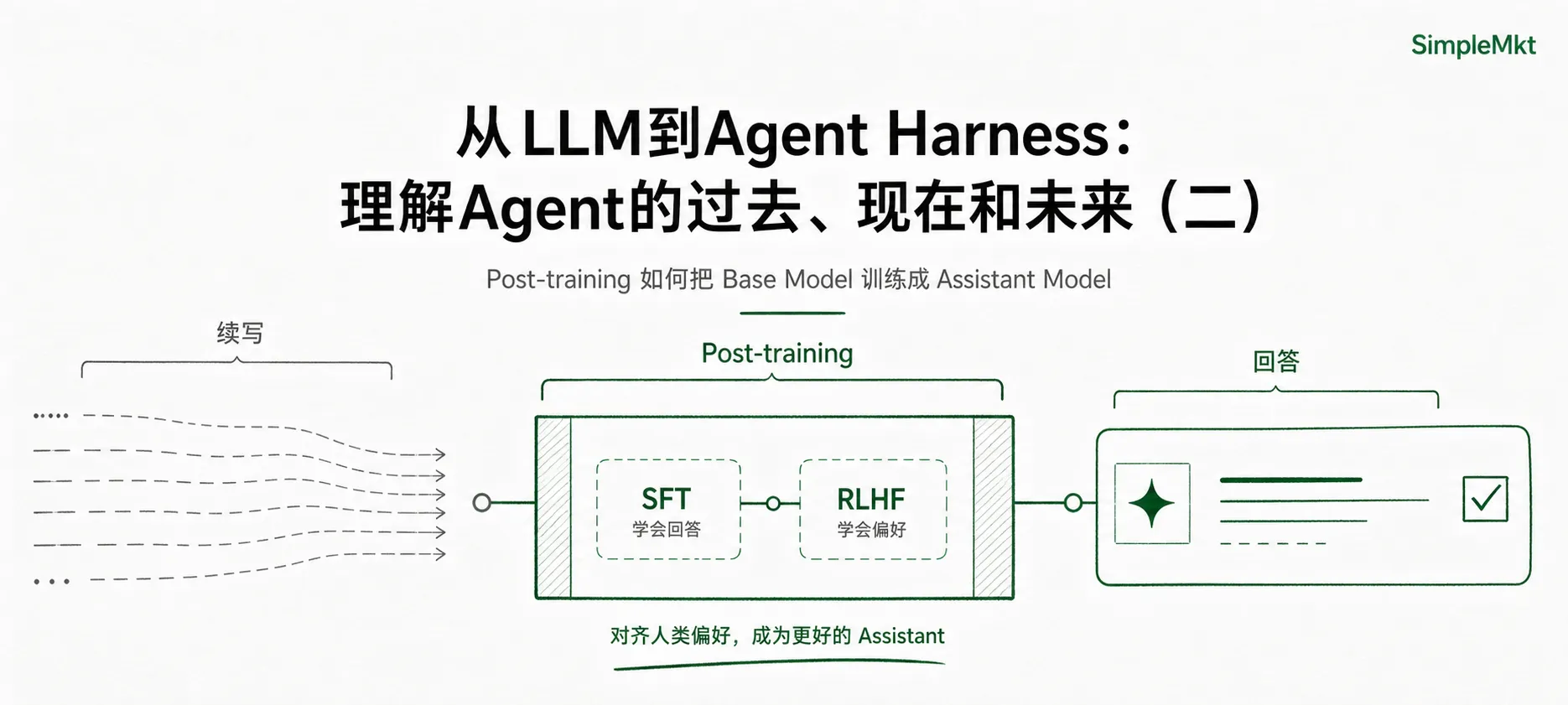
但这里有一个被很多人忽略的细节:裸 LLM 不是天生的聊天助手。 它可以续写出一段像对话的文字,也可能在提示词引导下完成一些任务,但它还没有被训练成一个稳定理解用户意图、角色关系和回答边界的助手。从裸 LLM 走到 ChatGPT 这种产品,中间有一个很重要的阶段叫 Post-training,后训练。
我这里说的裸LLM指的偏训练链路里的Base Model / Pretrained Model / 基座模型 / 基模。它主要通过大规模文本预训练学会“根据上文预测下一个 token”,但还没有被充分做成聊天助手。Stanford 对 foundation model 的经典定义是:在广泛数据上训练、通常以大规模自监督方式获得、并能被适配到很多下游任务的模型;而 LLM 只是其中偏语言的一类的基础模型,不等于全部基础模型。
所以这一篇要回答的是:一个只会续写的大脑,是怎么一步步变成ChatGPT这种Chatbot再到今天我们看到的 Claude Code、Codex 这样的能操作能行动的Agent 的?
我会沿着真实的工程路径往下推:先是Post- training(后训练)中的 SFT(监督微调)让模型开始模仿人类写出的好答案,RLHF 让模型进一步学习人类对“好回答”的偏好;然后是 Chatbot 在模型外面搭起多轮对话的结构,把原本连续的文本输入,整理成 system、user、assistant 这样的角色关系,让模型的输出真正进入“用户—助手”的交互场景;再往后,爆发的Prompt Engineering 和 Context Engineering 让人类能更稳定地控制模型的输入、边界和上下文;最后是 ReAct 和工具调用,让模型第一次不只是“说出答案”,而是开始“采取行动”,于是Claude code这类产品开始冒出,到了这个时候,“Agent”这个词才真正开始站得住。
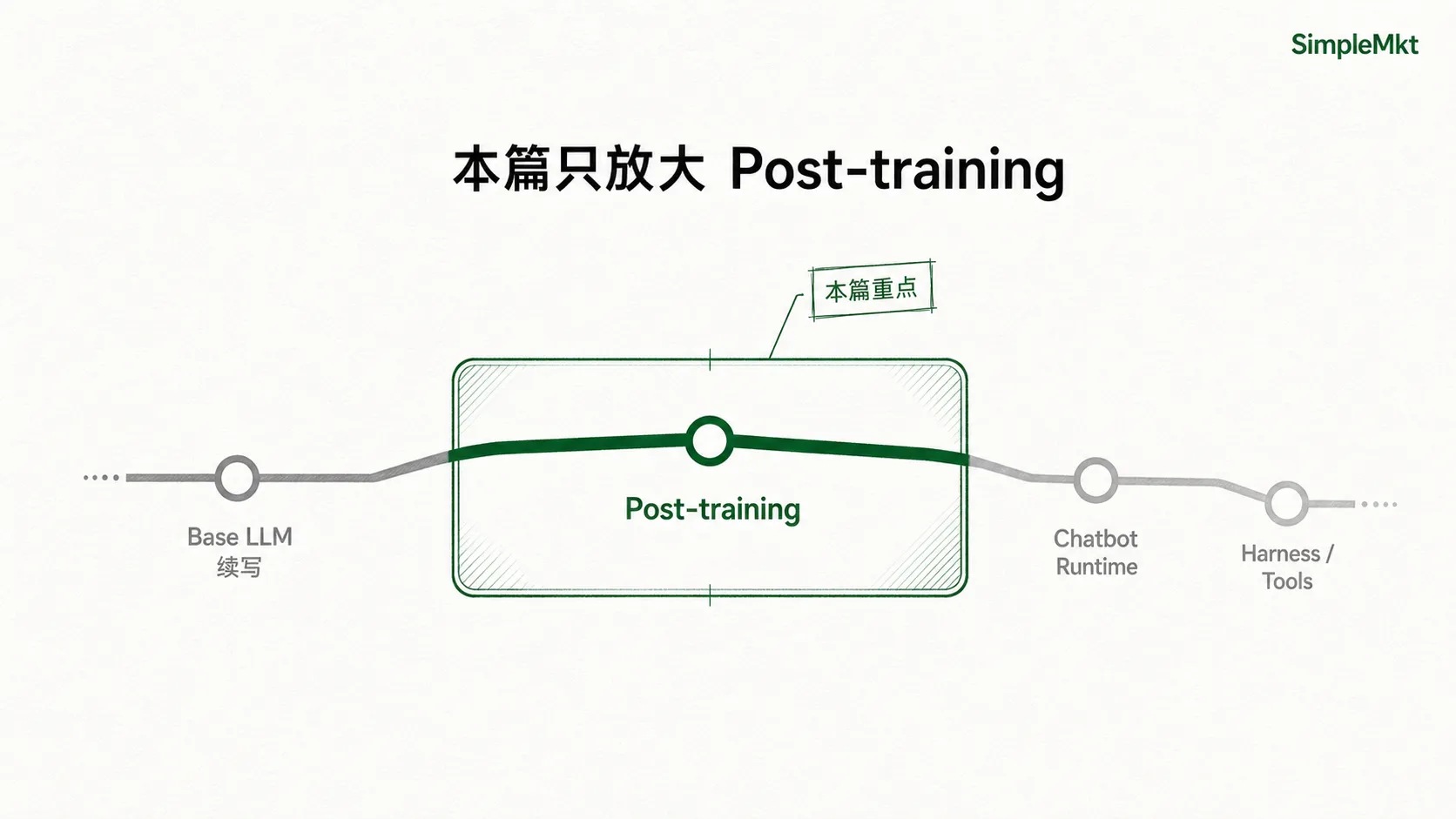
从续写到聊天:模型先去训练场,再走进剧场
模型变大,只是让它拥有了更强的语言能力、知识压缩能力和模式识别能力。但一个能力很强的模型,并不天然知道人类想要什么。你问它一个问题,它可能续写一段像论文的文字;你让它给建议,它可能生成一堆正确但没用的废话;你让它解释一个概念,它可能讲得很完整,却完全不适合普通人理解。
这就是裸 LLM 的问题:懂语言,但不懂场景;会生成,但不一定会回应;能给出内容,但不一定知道什么内容对人有用。
那么,怎么把一个”会续写的 LLM”变成一个”能服务人的 AI 助手”?
答案是:先把它送进训练场,再把它放进剧场。
- 第一步叫”训练场”——动模型本身的权重,让它学会”按指令回答”、按”人类更喜欢的方式回答”。这一层一旦完成,就改变了模型的回答习惯。它在业内对应的是 Post-training(后训练)。
- 第二步叫”剧场”——不再改模型权重,而是在模型外面搭一套运行时结构:谁是 system,谁是 user,哪里轮到 assistant 开口,上一轮对话要不要重新摆上桌面,最终怎么呈现在聊天窗口里。它让一个已经会回答的 Assistant Model,真正进入”用户—助手”的对话关系。
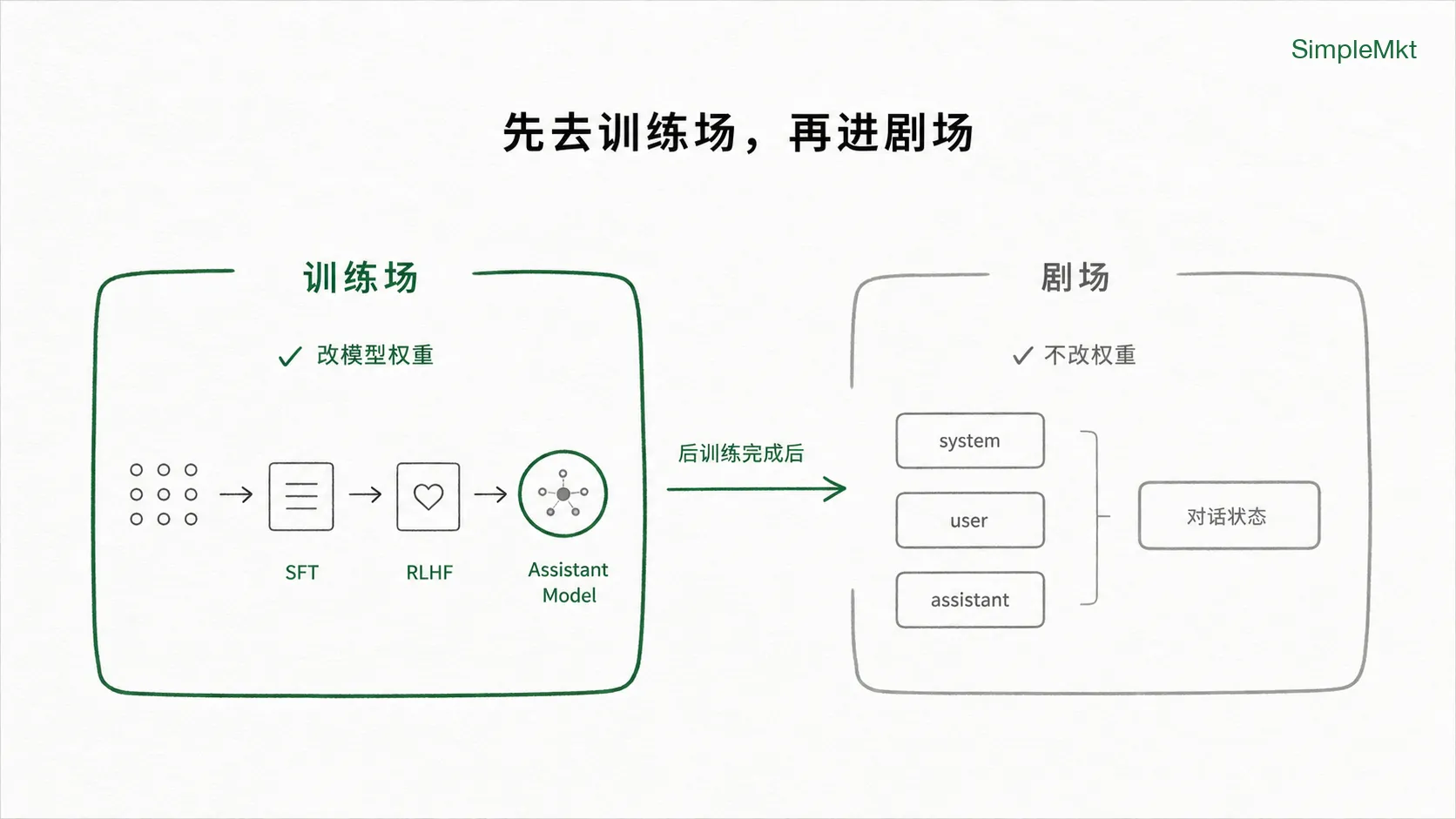
接下来我们先看训练场,再看剧场。
第一层:训练场 —— 把模型训成助手
先搭个脚手架:训练分两段
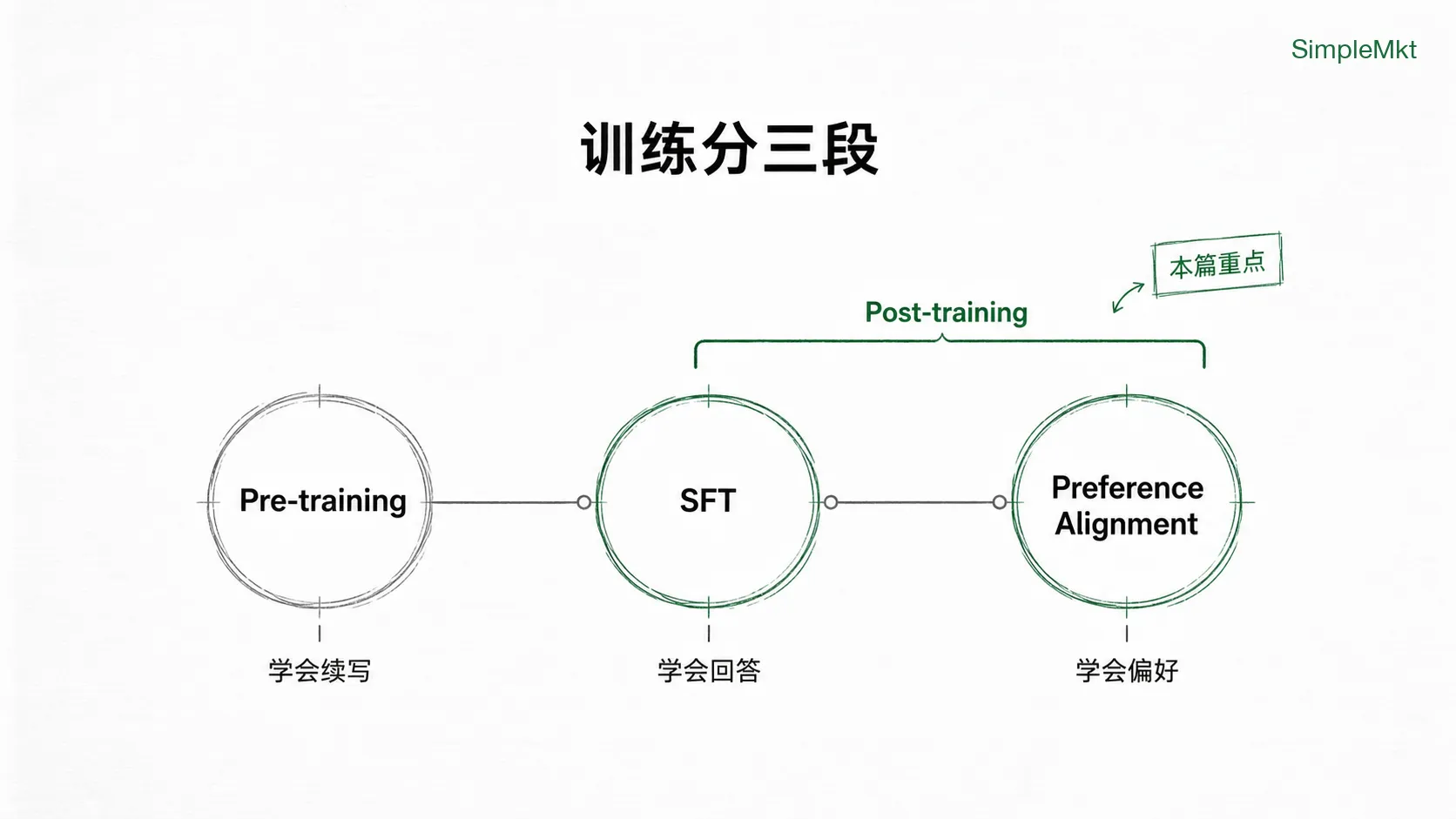
在讲”训练场”里具体发生什么之前,先把”训练一个能听话的 LLM”这件事拆成两段:预训练(Pre-training) 和 后训练(Post-training)。
- 预训练得到的是 Base Model(基座模型)——一个读遍互联网、什么都懂一点、但谁也不听的”白板天才”。
- 后训练则是一组让模型变得更可用、更可控、更像助手的方法。
为了更细致的理解,我们可以把整条链路拆成三个连续环节:
- 预训练(Pre-training):在万亿 token 量级的互联网文本上学”续写”。这一步决定了模型的基础能力——语言、常识、推理、代码、世界知识,它在让模型”读完世界上的书”并学会”世界上通常会怎么说话”。我们上一篇文章讲的 Scaling Law 和 Emergence,描述的就是这个阶段发生的事。这一步得到的模型一般被称为基础模型(Base Model)。
- 监督微调(SFT, Supervised Fine-Tuning):用人类写的”问题—理想回答”样本对模型做有监督训练,教它把”续写”扭成”回答”。它解决的是:模型能不能从一个续写机器,变成一个基本会听指令的聊天模型。
- 偏好对齐(Preference Alignment):当模型已经会回答之后,还要继续训练它理解人类更偏好哪种回答。多个答案可能都能用,但哪个更有帮助?哪个更诚实?哪个更安全?哪个更符合真实使用场景里的期待?RLHF 就是这个环节里最经典的一种方法。它不是简单给模型一个标准答案,而是让模型接受评委的比较和反馈,慢慢学会“什么样的回答更容易被人选中”。
SFT 和 RLHF 都属于广义上的”后训练”。区别在于,SFT 更像是”示范教学”——老师拿着标准答案教学生怎么答;RLHF 更像是”偏好塑形”——评委不告诉学生标准答案,只告诉他”这次比上次好/差”。
这三个环节的顺序大体不能乱:没有预训练,模型没有足够的知识和语言能力;没有 SFT,它很难从”续写”变成”回答”;没有偏好对齐,它就算会回答,也未必知道什么回答更有用、更克制、更安全。
本篇接下来重点展开后训练中的 SFT 和 偏好对齐下的RLHF ——它们是把模型从”会说话”推到”会服务”的经典临门两脚,也是”训练场”真正发生作用的位置。
目前你只需要先在脑子里挂上这张三阶段架构图即可,关于第一步的”预训练”的工程原理(Transformer 架构、tokenization、训练目标、损失函数等),未来或许我会专门出一个第零篇展开讲,感兴趣也可以关注并留意一下。
A. SFT:给模型做”助手岗位培训”
SFT 这一步要做的事情其实很纯粹:让裸 LLM 在该自己开口的位置上,说出像样的话。
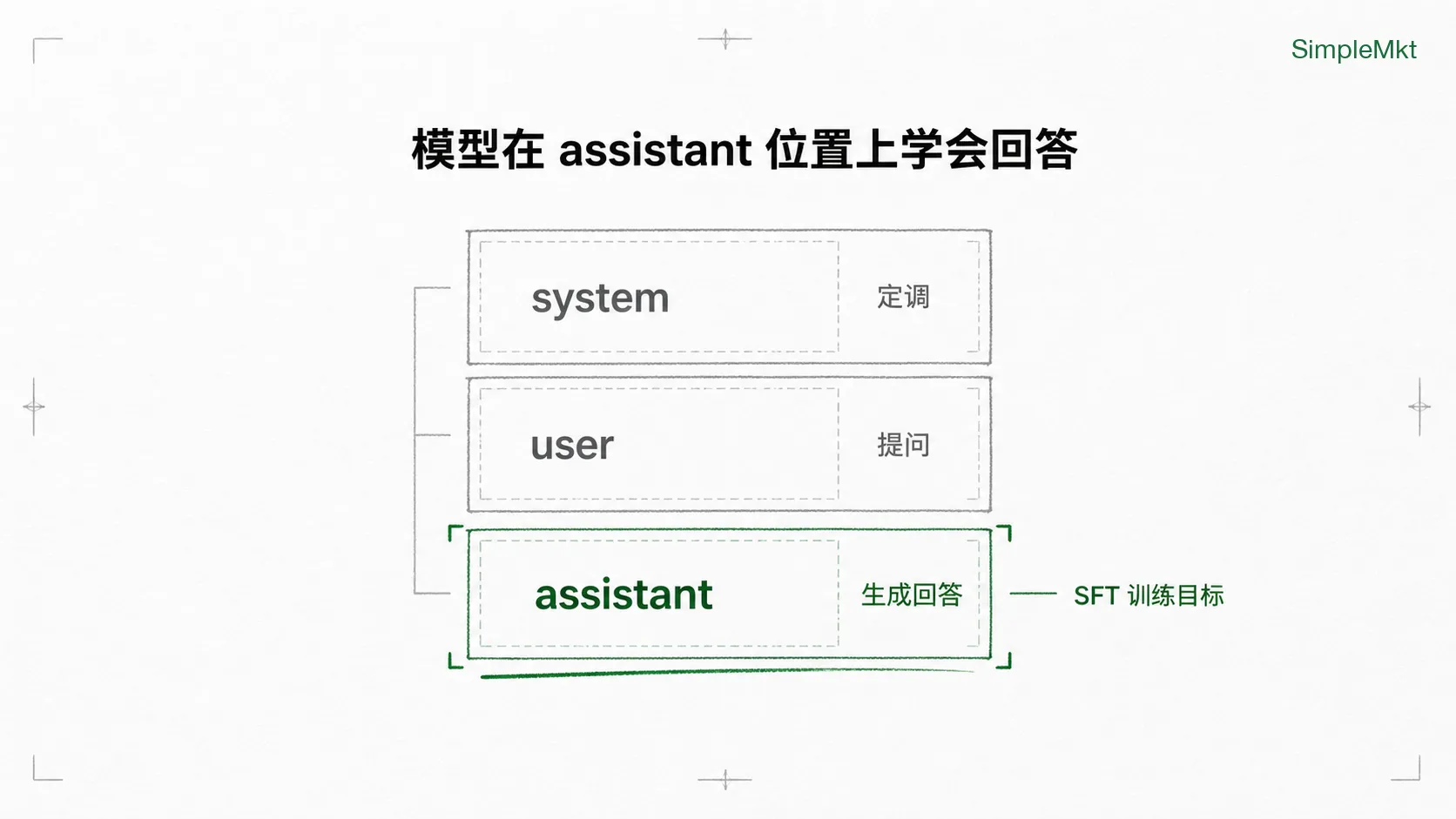
但”该自己开口的位置”是哪儿?这要从 LLM 对话的角色结构说起。为了让模型知道”谁在说话、什么时候轮到自己”,用户发给模型的每段对话,都会先被一些特殊标记(Special Tokens) 切成三个固定角色:
- system:定调子的”导演旁白”(比如”你是一个有帮助的助手”这种规则)
- user:观众席传上来的台词(用户真正发的内容)
- assistant:____(舞台上该 AI 接话的那个位置,也就是模型要生成回答的地方)
这套把对话整理成模型输入的规则,通常叫 Chat Template。不同模型的具体格式不完全一样,但你先认这三张脸就够了。
放到聊天模型语境里,SFT 要训练的,就是让模型在 assistant 这个该开口的位置上,说出符合指令的回答。 即用大量”指令—理想回答”成对的样本继续训练模型,让它把”在 assistant 位置上的续写”,扭成”在 assistant 位置上的回答”。当训练数据特别强调”自然语言指令 → 期望回答”这种形式时,这类 SFT 通常又叫 Instruction Tuning(指令微调)。
总的来说,SFT 可以理解成:给模型做一次”助手岗位培训”。老师拿着上万条标准答案,教学生:遇到总结题应该怎么答、遇到解释题应该怎么讲、遇到用户提问应该怎么组织语言。
但 SFT 还不够。因为很多真实问题没有唯一标准答案。
比如用户问:
我最近工作很焦虑,怎么办?
模型可能有几种回答:
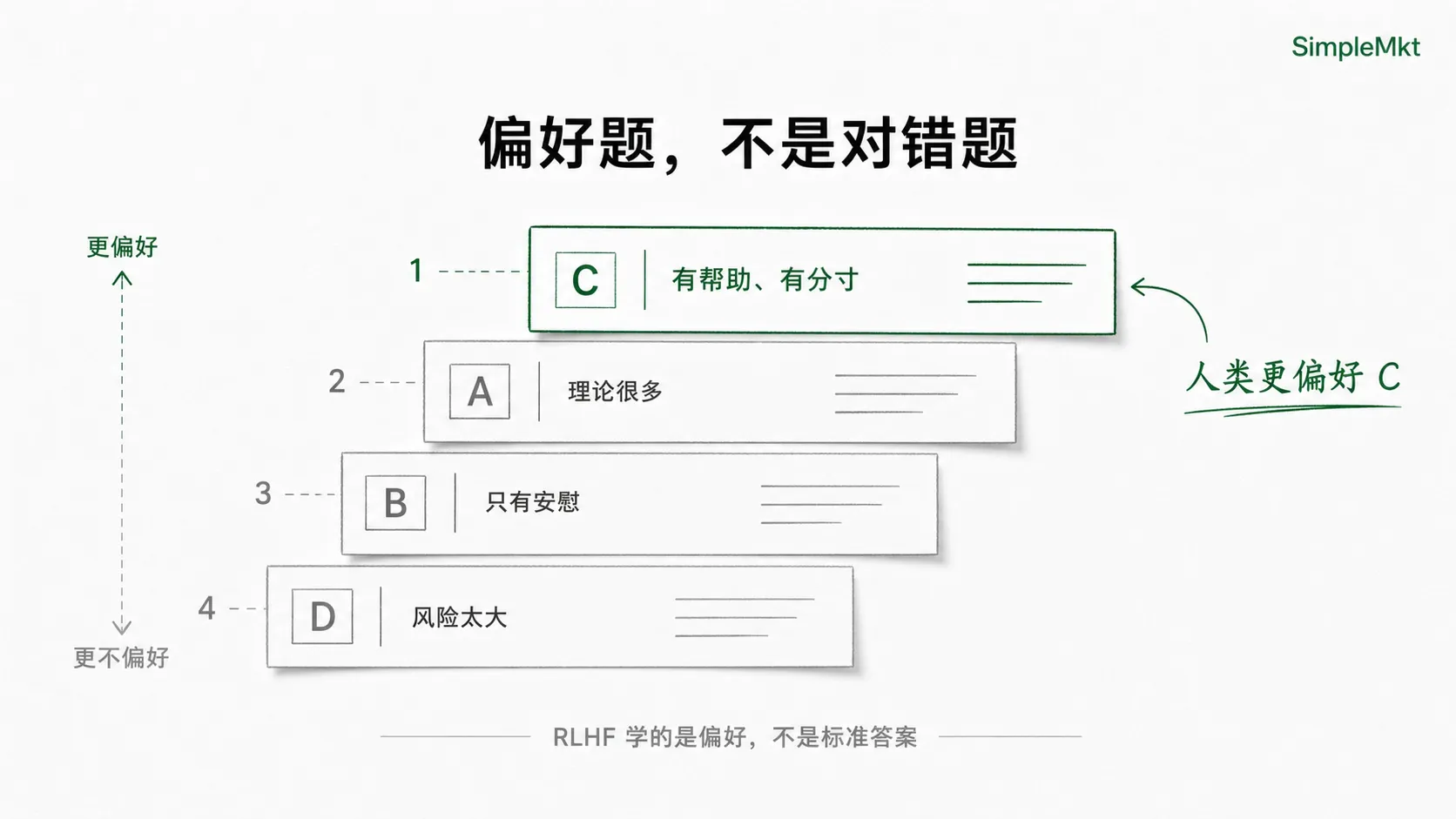
A:给一堆心理学理论。
B:说“别想太多,放轻松”。
C:先承认用户的感受,再帮他拆原因,最后给几个能执行的小动作。
D:直接建议辞职。这些回答不完全是“对错题”,而是“偏好题”。人类大概率会觉得 C 更好,因为它更有帮助、更有分寸,也更适合当下语境。
所以,还需解决一个问题——当多个回答都能成立时,模型应该更倾向于哪种一种回答? 即怎么才能让模型学会”按人类偏好的方式回答”?这就是RLHF要干的事情。
B. RLHF:请评委 + 让模型自己练
既然这种偏好题没有标准答案,老师就没法直接教了。RLHF 的解法是换一种教学方式——请一群评委,让模型在评委的反馈下自己练。 这事分三步走:
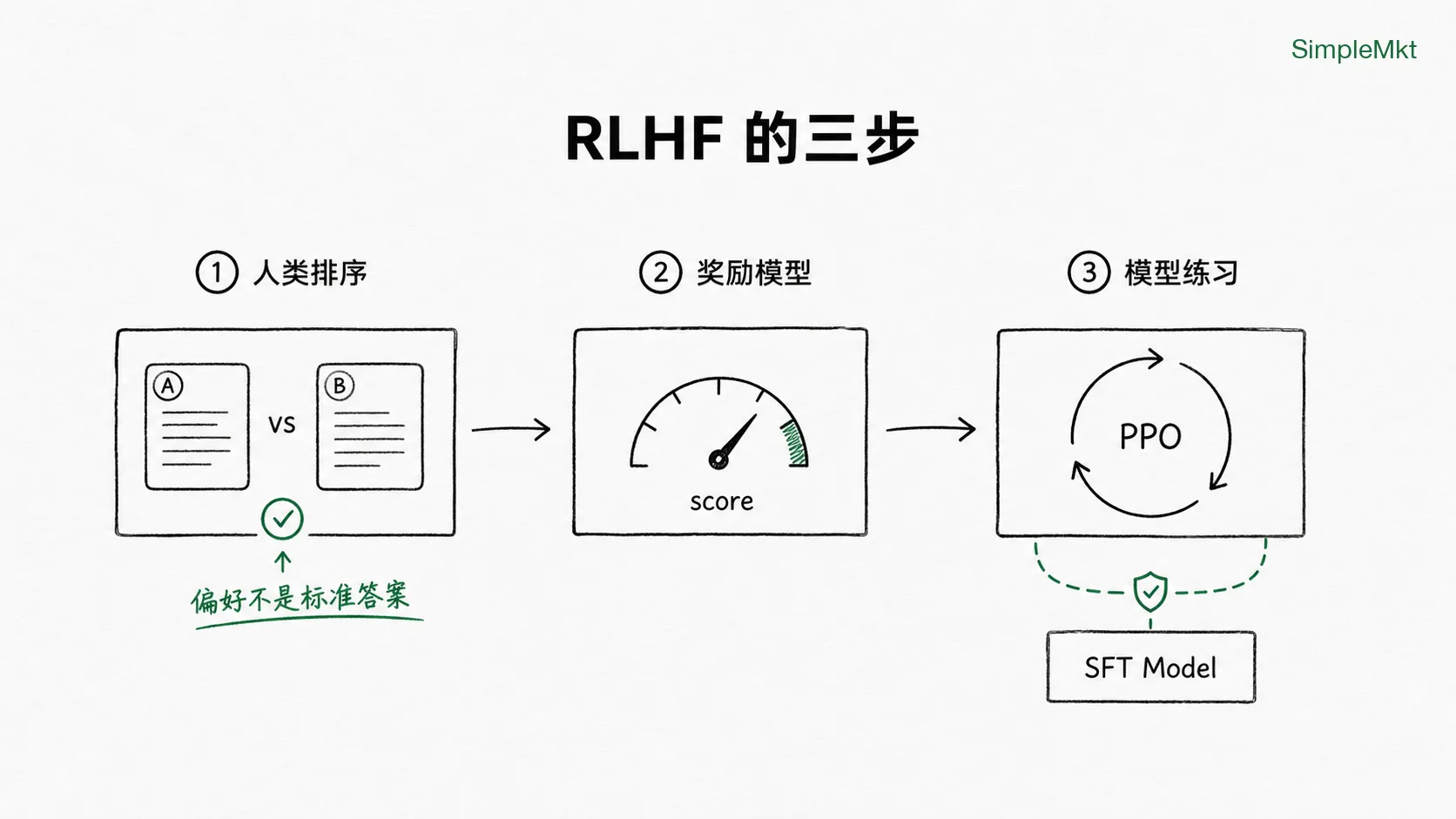
- 第一步:让评委表态。
给模型同一个问题,让它生成 4–9 个不同回答,再请人类标注员排序。
“这几个里 C 最好、B 次之、A 最差”。
注意:评委不写答案,只比较。
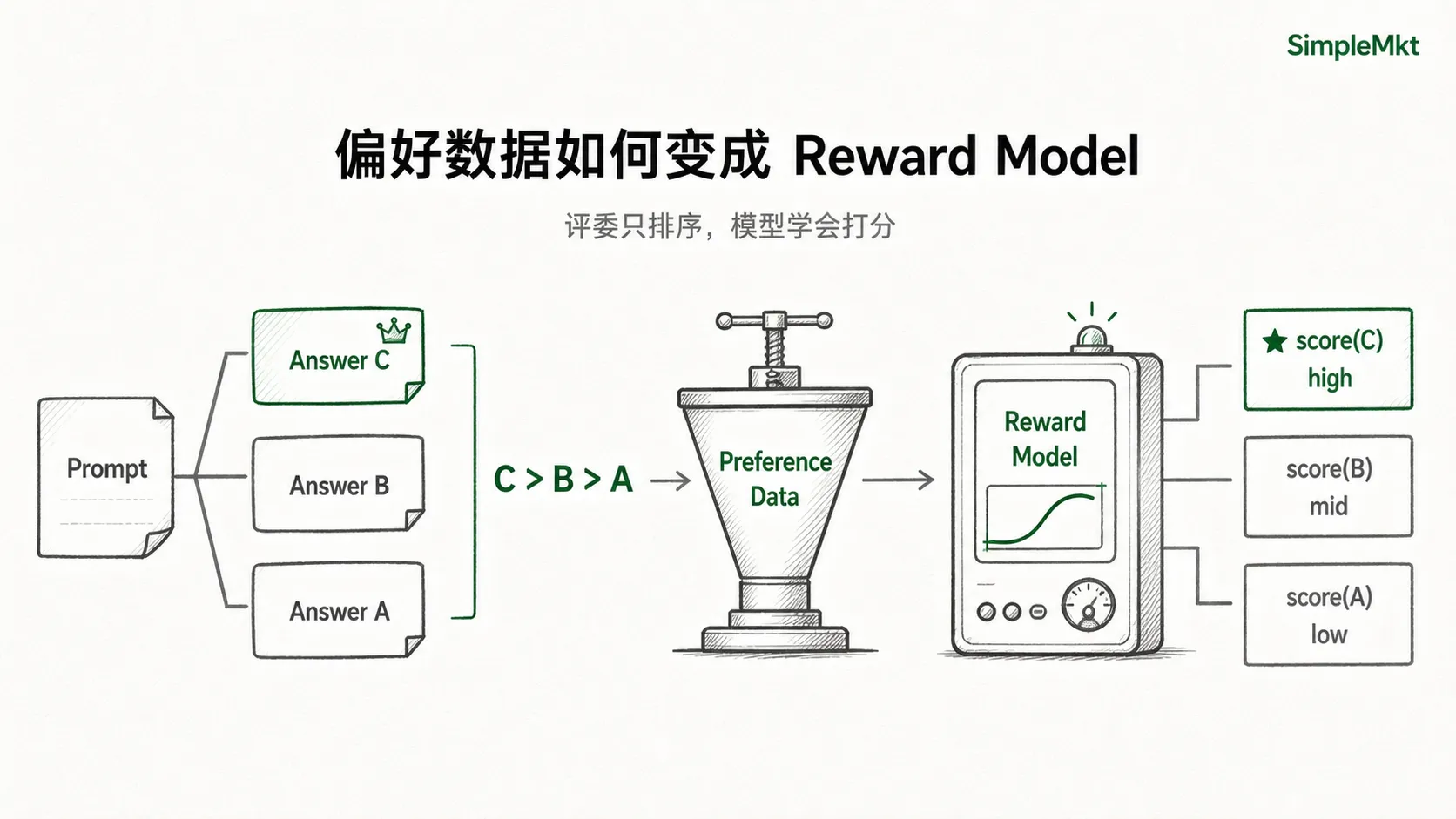
比如,用户问:用大白话解释什么是通货膨胀。模型生成两个回答:
- 回答A:通货膨胀是一般价格水平持续上涨的宏观经济现象……
- 回答B:通货膨胀可以理解为钱变得没那么值钱了。以前 10 元能买一碗面,现在可能要 15 元……
人类标注员可能会针对上面的A和B进行判断,给到结论:B比A更好,于是整个链路呈现出来的是——问题 → 回答 A vs 回答B → 人类更喜欢B。
这就是偏好数据。
- 第二步:把评委的品味压成一台机器去打分
问题是,人类不可能永远都站在边上给模型打分吧?
于是他们用这些排序数据训练一个奖励模型(Reward Model, RM)——它的任务不是生成回答,而是给回答打分。SFT Model 输入”问题+回答”,Reward Model 输出一个分数。
本质上是把”人类偏好”这件事,压缩进了一个新的神经网络,从此每个回答都能被自动打分。Reward Model的训练方式大概是这样:如果人类认为 B 比 A 好,那奖励模型就要学会:score(B) > score(A)。
接着我们上面那个例子,RewardModel输出的是:
RewardModel(prompt, answer A) = 2.1
RewardModel(prompt, answer B) = 3.5
RewardModel(prompt, answer C) = 5.8
RewardModel(prompt, answer D) = 1.8- 第三步:模型开始在自动评委的反馈下练习回答
到了这一步,人类评委已经不需要每次都站在旁边了。因为前面训练出的 Reward Model,已经能临时代替人类,给模型的回答打分。
于是训练过程变成这样:
模型先生成一个回答,Reward Model 给它一个分数。分数高,说明这种回答更接近人类偏好;分数低,说明这种回答不太合适。模型再根据这个分数调整自己:以后更容易生成高分回答,更少生成低分回答。
这就像学生练作文,第一步,老师看几篇作文,判断”哪篇更好”;第二步,把老师的判断整理成一套自动评分器;第三步,学生反复写,评分器反复打分,学生根据分数一点点调整自己的写法。
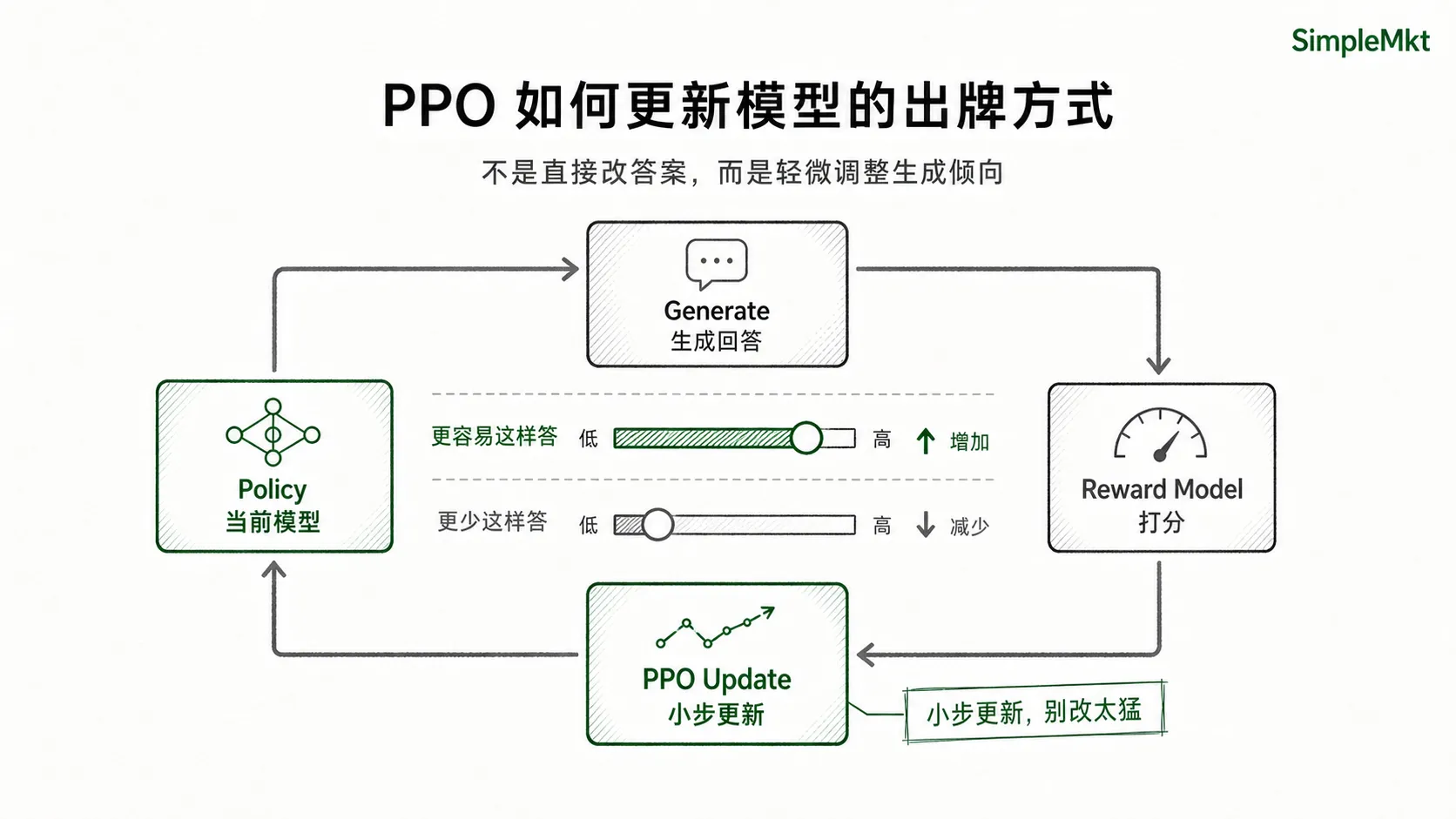
技术上,InstructGPT 这条经典路线在第三步用了一个叫 PPO 的强化学习算法。你不需要把它理解成一套复杂公式,先抓住两句话就够了:
PPO 就像训练时的”改作业规则”:哪种回答被奖励模型打高分,就让模型以后更容易这么答;哪种回答被打低分,就让模型以后少这么答。
PPO 本身是一个强化学习算法,最早并不是专门为语言模型发明的。它属于一类叫 policy gradient 的方法。这里的 policy 不是”政策”,而是模型当前的”出牌方式”:面对一个输入,它更倾向于选哪些词、用什么语气、按什么结构回答。PPO 做的事,就是根据奖励分数,慢慢调整这套出牌方式,同时避免模型一次改得太猛。
但这里还有一根安全绳:模型不能只为了拿高分而乱学。训练时通常还会加一个惩罚项,限制它不要偏离原来的 SFT 模型太远。
否则会出现一种问题,叫 reward hacking(奖励投机):模型发现某些套路能骗过评分器,比如疯狂礼貌、过度迎合、说很多看似负责但没信息量的话,于是它开始刷分,而不是真的变好。说白了,就是在“钻奖励函数的空子”。
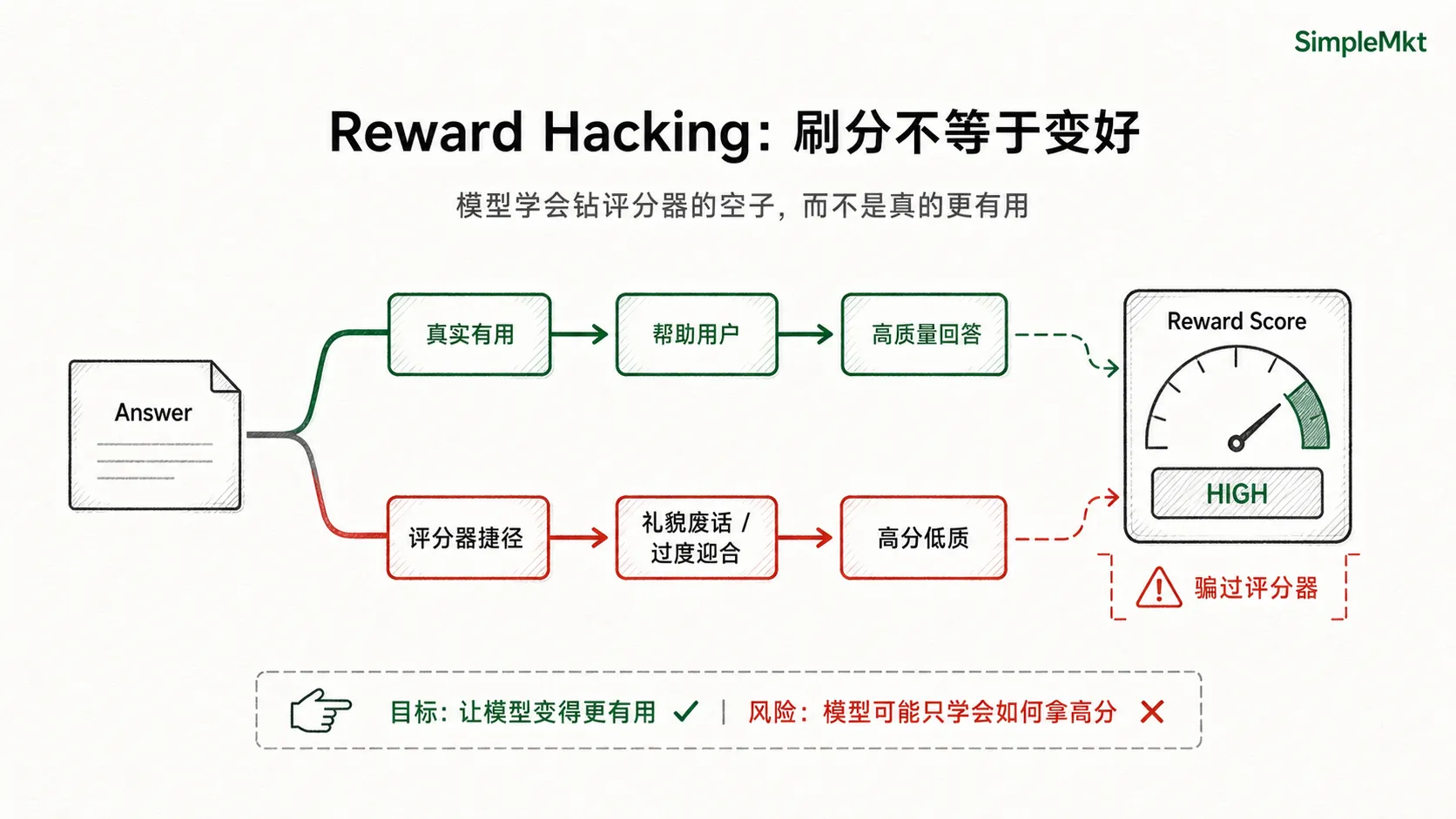
所以更准确地说,RLHF 第三步优化的不是单纯的”分数越高越好”,而是:
尽量获得更高奖励,同时不要偏离原来的模型太远。
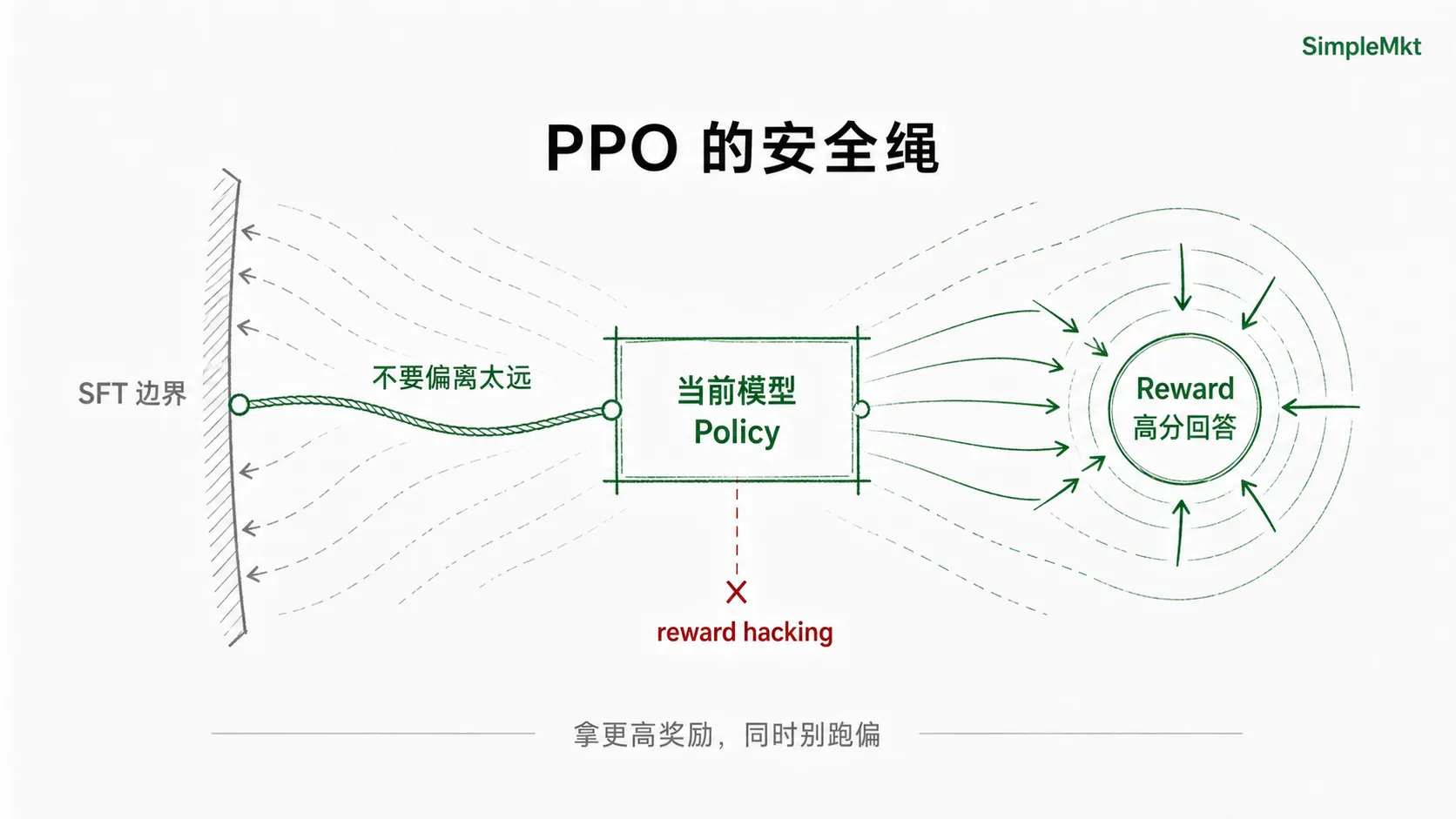
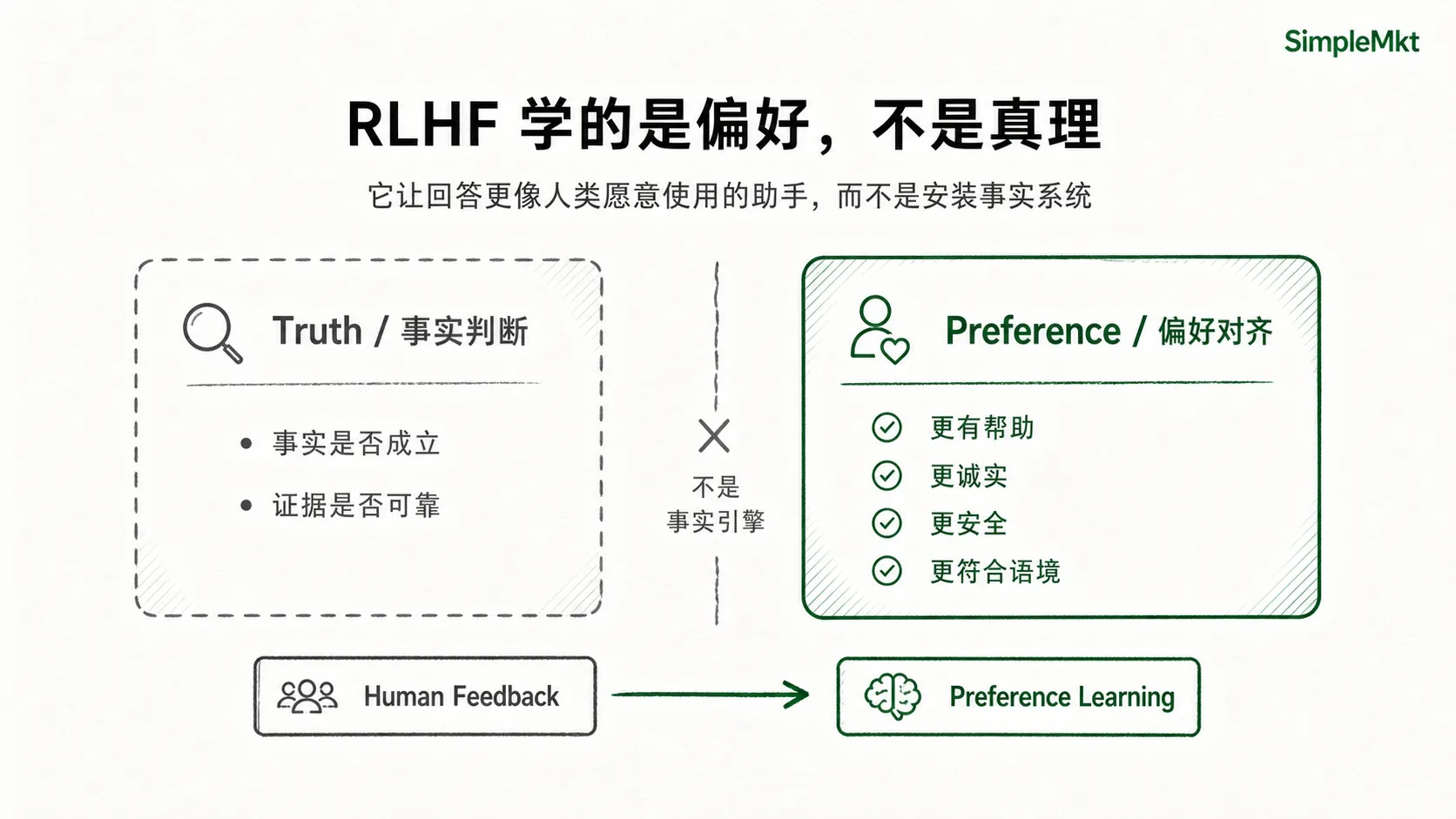
这也说明了 RLHF 的本质边界:它不是在给模型安装一套真理系统,而是在训练模型更接近人类评委偏好的回答方式。
这些偏好通常会被训练指南引向几个方向:更有帮助、更诚实、更安全,也更符合当下语境。
所以一句话概括:RLHF 不是教模型什么是真的,而是教模型什么样的回答更像一个人类愿意继续使用的助手。
C. 第一层完成:Base Model → Assistant Model
上面这套机制最有代表性的公开案例,是 OpenAI 在 2022 年 3 月发表的 InstructGPT 论文:《Training Language Models to Follow Instructions with Human Feedback》。
这篇论文把 SFT、奖励模型和 PPO 串成了一条完整的后训练流水线:先让模型学会像助手一样回答,再让模型根据人类偏好继续调整自己的回答方式。
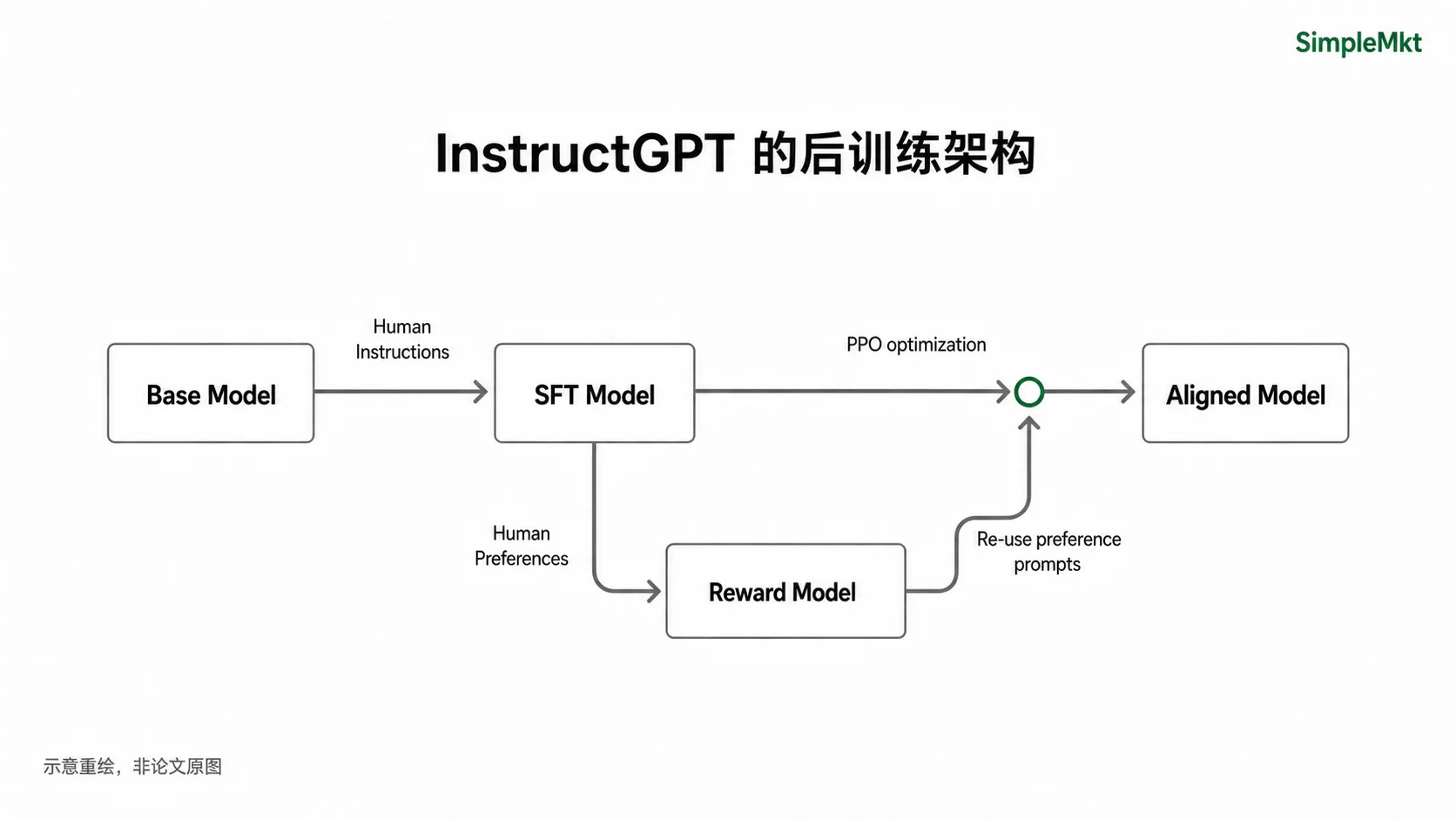
论文里最有冲击力的结果是:在这篇论文测试的 API prompt 分布里,1.3B 参数的 InstructGPT 输出,在人类评估中比 175B 参数的原始 GPT-3 更受偏好。
在经典 InstructGPT 流水线里,SFT 通常作为 RLHF pipeline 的第一步出现;但严格区分概念时,SFT 是后训练中的监督微调,RLHF 是后训练中的偏好对齐方法。
这说明一件事:模型变大,不等于自然会服务人。“听话”不是规模的副产品,而是一个独立的工程问题。

经过这层后训练,Base Model 就不再只是一个会续写文本的基础模型,而开始变成一个能按指令回答、能理解用户意图、回答方式更接近人类偏好的助手模型。
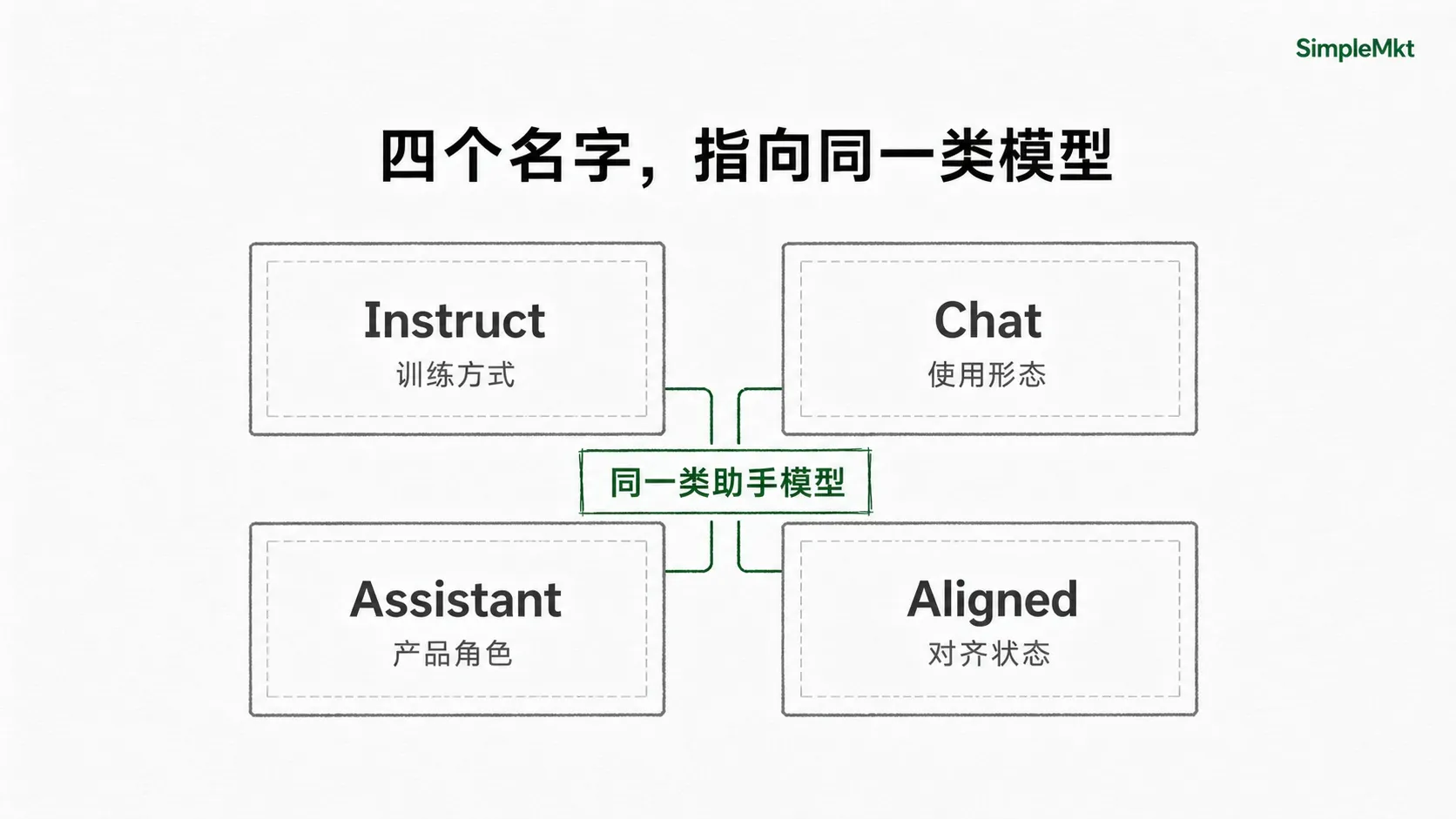
这个阶段的成品,在不同语境里会有几种常见叫法:
- Instruct Model:强调它经过指令微调,能按指令完成任务。
- Chat Model:强调它适合被放进对话产品里使用。
- Assistant Model:强调它的产品角色是”助手”。
- Aligned Model:强调它经过了某种对齐训练,更贴近人类偏好和安全边界。
这几个词在产品语境里经常会重叠,但侧重点不同: Instruct 说的是训练方式,Chat / Assistant 说的是交互形态和产品角色,Aligned 说的是模型已经被往人类意图和安全边界上拉过一轮。
所以你可以先建立这一组关系:
Base Model
↓ Post-training(SFT + RLHF + 后续偏好优化)
Assistant / Instruct / Chat / Aligned Model其中,Post-training(后训练) 是更大的概念;Alignment(对齐) 是后训练里专门处理”模型如何更贴近人类意图和偏好”的那部分。
但到这里,还没结束,它还只是”从训练场毕业”的模型,不等于 ChatGPT 这样的完整产品。
原因很简单:模型本身仍然只是一个输入输出引擎。你给它一段输入,它生成一段输出。它可以学会在 assistant 位置上回答,但它不会天然拥有聊天窗口、历史记录、用户界面,也不会自己管理一轮又一轮的对话状态。
要让它变成真正的 Chatbot,还需要第二层:把这个助手模型放进一套运行时结构里。
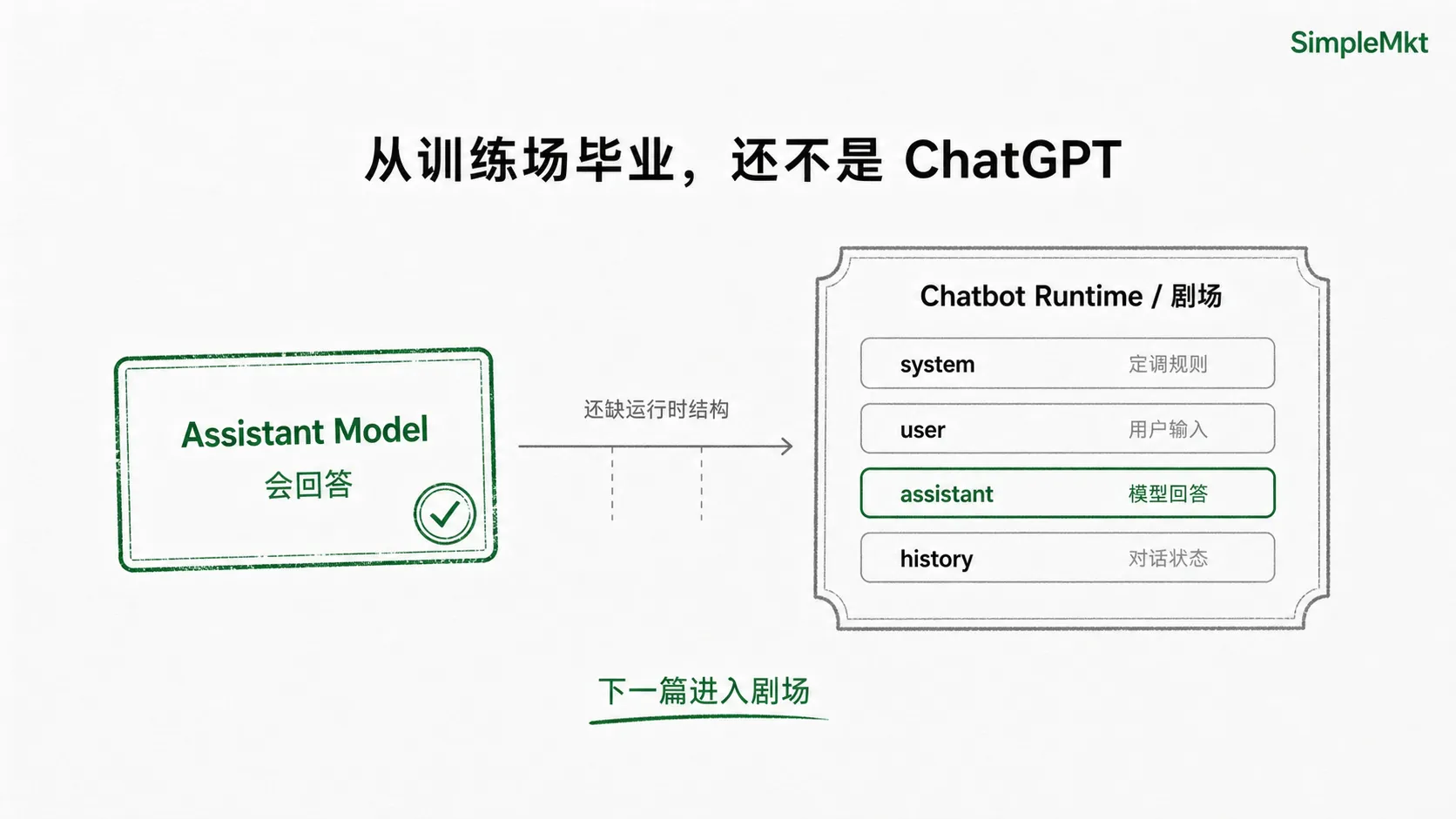
这就是下一层——剧场。我们下一篇文章会讲。
- 主笔:炼金术士周冷清
- AI 辅助:Codex + GPT5.5、Claude Code + opus4.8
- 辅助内容:资料整理、结构讨论、事实核查、文本润色、配图生成